


Become a Data Engineer: Skills, Salaries & Career Path

What is a Data Engineer?
A Data Engineer is a specialized IT professional responsible for designing, building, and maintaining scalable, efficient, and reliable systems to manage an organization’s data lifecycle. These professionals are the backbone of data operations, ensuring that raw data collected from multiple sources is transformed into structured and usable formats for analysis, business intelligence, and machine learning.
Key Characteristics of a Data Engineer
Architect of Data Systems:
Data Engineers design the architecture for large-scale data pipelines, integrating various data sources and ensuring seamless data flow to downstream systems. They are responsible for creating systems that handle massive data volumes, often using distributed computing frameworks such as Hadoop, Spark, or Kafka.
Curator of Data Quality:
They implement processes to clean, transform, and validate data, ensuring it meets organizational quality standards. This involves removing inconsistencies, handling missing data, and ensuring accuracy.
Bridge Between Data and Decision-Making:
While Data Scientists and Analysts focus on insights and modeling, Data Engineers build the foundational infrastructure and tools necessary to make data analysis possible. Without their systems, business-critical insights would be impossible to derive.
Expert in Data Storage:
They manage data storage systems, such as relational databases (MySQL, PostgreSQL) and NoSQL databases (MongoDB, Cassandra). Data Engineers also design and maintain data warehouses and data lakes (e.g., Snowflake, Redshift, BigQuery) to optimize data retrieval and storage.
Scalability and Performance:
As data volumes grow, ensuring that pipelines and systems remain fast and efficient is a core responsibility. Data Engineers implement optimization techniques and scaling strategies to meet performance requirements.
Collaborators Across Teams:
They work closely with Data Scientists, Analysts, and DevOps teams to align data infrastructure with analytical and business needs. This collaboration ensures that the right data is delivered to the right people in the right format.
Roles and Responsibilities of Data Engineers
- Data Pipeline Development: Build and maintain automated ETL pipelines for data extraction, transformation, and loading.
- Database Management: Design and manage relational and NoSQL databases, ensuring efficient storage and access.
- Data Warehouse Management: Build and maintain data warehouses for structured, integrated data.
- Data Quality & Cleansing: Validate, clean, and transform raw data into usable formats.
- Big Data Handling: Use big data tools (e.g., Hadoop, Spark) to process large datasets.
- Automation: Automate data workflows to reduce manual work and ensure consistency.
- Data Security & Governance: Implement encryption, access controls, and ensure data compliance (e.g., GDPR, HIPAA).
- Collaboration: Work with Data Scientists, Analysts, and DevOps to align data infrastructure with organizational needs.
- Monitoring & Troubleshooting: Monitor data systems, debug issues, and optimize performance.
- Cloud Platform Management: Work with cloud services (e.g., AWS, Google Cloud) for scalable data solutions.
- Documentation: Document data architecture, processes, and workflow status for collaboration and maintenance.
What is Data Engineering?
Data Engineering is the field of designing, building, and maintaining systems that allow organizations to collect, process, store, and analyze large volumes of data. It involves creating the infrastructure and tools needed to ensure data flows seamlessly across systems, is of high quality, and can be used effectively for business decisions, analysis, and machine learning.
In essence, Data Engineering focuses on the architecture and infrastructure that powers data-driven operations and ensures that data is accessible, reliable, and scalable. Data Engineers are responsible for transforming raw data into a format that can be easily analyzed by data scientists, analysts, or business teams.
Key Components of Data Engineering
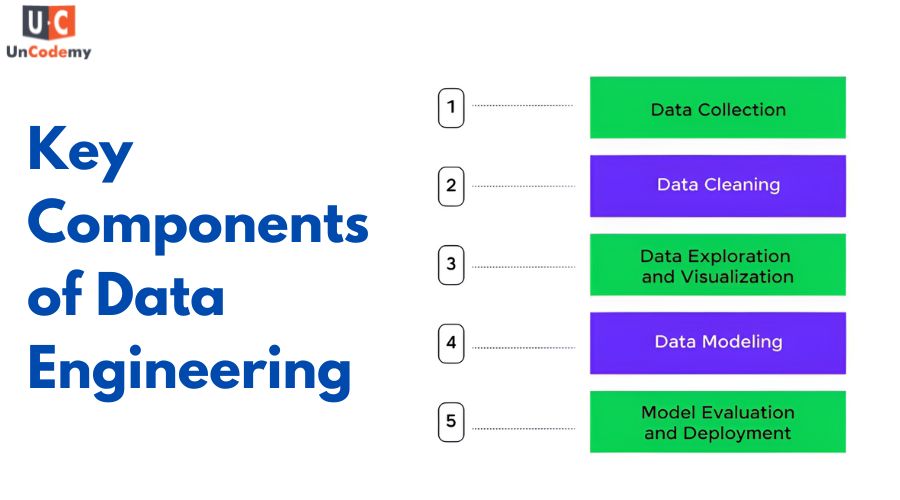
Data Pipelines:
Data Engineers design and develop data pipelines that automate the extraction, transformation, and loading (ETL) of data from various sources into storage systems or data warehouses.
Data Storage Solutions:
They work with databases, data lakes, and data warehouses to store large datasets efficiently. These systems can be either on-premises or cloud-based. They ensure data is well-organized and optimized for fast retrieval and analysis.
Data Integration:
Data Engineers integrate data from multiple sources, such as APIs, databases, and external datasets, and ensure it is available in a unified format.
Big Data Processing:
With the advent of big data, Data Engineers manage and process large-scale datasets using distributed computing frameworks like Hadoop, Apache Spark, and Kafka. This enables processing data in parallel across many machines for scalability and speed.
Data Quality and Integrity:
Data Engineers implement processes to clean, validate, and ensure the accuracy and consistency of data. This is critical to ensure that downstream users, such as data scientists or analysts, can rely on the data for decision-making.
Automation:
Automation is a key aspect of Data Engineering. Data Engineers automate repetitive data processes such as data extraction, transformation, and loading, reducing human intervention and speeding up workflows.
Data Security:
Ensuring that data is secure is crucial. Data Engineers implement encryption, access controls, and compliance measures to protect sensitive information, following regulations such as GDPR or HIPAA.
Scalability:
Data Engineers design systems that can scale to handle increasing data volumes. They use distributed systems, cloud platforms, and efficient data processing methods to ensure performance remains optimal as data grows.
Why is Data Engineering Important?
In today’s data-driven world, organizations rely heavily on data to make informed decisions, optimize processes, and drive innovations. However, raw data from various sources is often messy, inconsistent, and unstructured. Data Engineering ensures that the right data is available at the right time, in the right format, for the right stakeholders.
Without Data Engineering, businesses would struggle to effectively collect, process, and leverage their data. It serves as the backbone of data science and analytics, enabling advanced techniques like machine learning, predictive analytics, and business intelligence
Tools and Technologies Used in Data Engineering
Databases: SQL-based databases (MySQL, PostgreSQL) and NoSQL databases (MongoDB, Cassandra).
ETL Tools: Apache NiFi, Apache Airflow, Talend, Informatica.
Big Data Frameworks: Hadoop, Apache Spark, Apache Kafka.
Cloud Platforms: AWS (Redshift, S3), Google Cloud (BigQuery, Cloud Storage), Microsoft Azure (Data Lake, Azure SQL).
Data Warehouses: Snowflake, Redshift, Google BigQuery.
Data Modeling: Tools for designing schema, relational models, and dimensional models.
Vacancies in Data Engineering
In India, the job market for Data Engineers is thriving, with numerous opportunities across various industries. As more organizations embrace data-driven decision-making, companies are actively seeking skilled professionals to design, build, and maintain robust data infrastructures. This growing demand for Data Engineers makes it an excellent time to enter the field, especially with the right training.
Pursuing a Data Engineering course from us can equip you with the necessary skills and knowledge to succeed in this competitive environment. The course will prepare you to handle the technical challenges involved in data processing, storage, and management, ensuring that you’re ready to meet the needs of top employers in the industry.
Some of the leading companies in India currently offering job vacancies for Data Engineers include TCS (Tata Consultancy Services), Infosys, Wipro, HCL Technologies, IBM India, Accenture, Capgemini, Deloitte, PwC (PricewaterhouseCoopers), and Cognizant. Other notable employers are Tech Mahindra, EY (Ernst & Young), KPMG, ZS Associates, SAP Labs, J.P. Morgan, Bank of America, HDFC Bank, ICICI Bank, and Larsen & Toubro (L&T).
These companies are actively looking for professionals with a solid background in Data Engineering, making it an ideal opportunity for those looking to advance their careers in the field.
Salary Packages for Data Engineering Professionals
The salary packages for Data Engineering professionals vary depending on factors such as experience, location, and industry. Here’s an overview of the typical salary ranges for professionals in this field:
Entry-Level Data Engineer: Fresh graduates or those with 1-2 years of experience can expect salaries ranging from INR 4-7 lakhs per annum, depending on the company and location.
- Mid-Level Data Engineer: With 3-5 years of experience, professionals can earn between INR 7-12 lakhs per annum. At this level, Data Engineers often manage and optimize data pipelines, work with databases, and help integrate data across systems.
- Senior Data Engineer: For those with over 5 years of experience, salaries typically range from INR 12-20 lakhs per annum. Senior Data Engineers are responsible for designing complex data architectures, ensuring the scalability of data systems, and leading large-scale data initiatives.
- Lead Data Engineer: At the leadership level, Data Engineers with extensive experience (8+ years) can earn INR 20-30 lakhs per annum, with responsibilities including overseeing data infrastructure, managing teams, and making high-level architectural decisions.
- Specialized Data Engineer: Data Engineers with expertise in big data technologies (e.g., Hadoop, Spark), cloud platforms (AWS, Azure), or advanced data processing can command salaries in the range of INR 15-30 lakhs per annum, depending on the complexity and scale of the organization.
These salary figures can increase significantly for professionals working in top-tier companies or those with specialized skills in emerging technologies, cloud computing, or machine learning. The demand for skilled Data Engineers is high, making it a lucrative and rewarding career path.
Roadmap to become a Data Engineer
To become a Data Engineer, you need to acquire a combination of technical skills, hands-on experience, and knowledge of the tools and technologies used in the field. Here is a step-by-step guide to help you navigate the journey:
Develop a Strong Foundation in Programming
Learn Python and SQL: These are the core programming languages for data manipulation and querying databases.
Python: Focus on libraries like Pandas, NumPy, and PySpark (for big data processing).
SQL: Understand database design, querying, and optimization techniques (JOINs, GROUP BY, indexing, etc.).
Optional: Learn Java or Scala, as they are commonly used in big data tools (e.g., Apache Spark).
Understand Data Engineering Concepts
Databases and Data Storage: Learn about relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra).
Data Modeling: Understand how to structure and organize data efficiently using relational and dimensional models.
ETL (Extract, Transform, Load): Learn how to build data pipelines for transforming and loading data from different sources to data storage solutions.
Learn Data Processing Tools and Frameworks

Big Data Tools: Study tools such as Apache Hadoop, Apache Spark, and Kafka for handling large volumes of data.
Data Pipelines: Learn to automate data workflows using tools like Apache Airflow, NiFi, or other ETL frameworks.
Data Warehousing: Understand the architecture and principles behind data warehouses (e.g., Snowflake, Redshift, BigQuery).
Gain Cloud Platform Expertise
Cloud Services: Learn how cloud platforms (AWS, Azure, Google Cloud) support data storage, processing, and analytics.
AWS: Focus on S3 (data storage), Redshift (data warehousing), Lambda (serverless computing), and Glue (ETL).
Google Cloud: BigQuery (data warehousing), Cloud Storage (data storage), Dataflow (data processing).
Azure: Azure SQL, Azure Data Lake, Azure Synapse Analytics.
Work on Real-Time Data Processing
Learn how to handle real-time data streaming using tools like Apache Kafka and Apache Flink.
Understand message queuing systems and stream processing techniques to manage data flow in real time.
Focus on Data Security and Governance
Data Security: Understand encryption, data masking, and secure data storage techniques.
Compliance: Learn about data privacy laws like GDPR and HIPAA.
Access Control: Implement role-based access control (RBAC) and audit mechanisms to manage who has access to data.
Work on Hands-On Projects
Build data pipelines from scratch using public datasets. Examples:
Collecting and processing data from APIs or web scraping.
Creating a data pipeline to load raw data into a data warehouse.
Processing large datasets using Apache Spark or Hadoop.
Contribute to open-source projects or collaborate on projects to demonstrate your skills.
Master Data Warehousing Concepts
Learn how to build and maintain data warehouses that aggregate data from various sources and enable business intelligence.
Understand OLAP (Online Analytical Processing) and OLTP (Online Transaction Processing) systems and how they differ.
Study tools like Snowflake, Redshift, and BigQuery for creating and managing data warehouses.
Pursue Relevant Certifications (Optional)
Cloud Certifications: AWS Certified Data Analytics, Google Cloud Professional Data Engineer, Azure Data Engineer.
Big Data and ETL Tools: Get certifications in Apache Hadoop, Apache Spark, or specific ETL tools (e.g., Talend).
Database Management: Certifications like MySQL or PostgreSQL can help demonstrate your database expertise.
Build a Strong Portfolio
Showcase your projects in an online portfolio, such as GitHub or a personal website.
Include code snippets, documentation, and details about the tools used.
Share how you solved specific data challenges or optimized workflows.
Apply for Entry-Level Data Engineering Roles
Look for job titles like Junior Data Engineer, ETL Developer, Data Analyst, or Database Administrator to gain experience.
Build your network on LinkedIn and attend industry events or meetups to connect with other data professionals.
Prepare for interviews by studying common Data Engineering interview questions related to data modeling, pipeline design, and system optimization.
Continue Learning and Evolving
Stay updated with new technologies and trends in data engineering.
Participate in online communities like Reddit’s r/dataengineering, Stack Overflow, or LinkedIn groups to exchange knowledge and keep learning.
Proposed Timeline
Months 1–3: Learn Python, SQL, and basic databases.
Months 4–6: Dive into data modeling, ETL tools, and cloud platforms.
Months 7–9: Focus on big data tools (Hadoop, Spark), real-time processing, and advanced data engineering concepts.
Months 10–12: Work on hands-on projects, contribute to open-source, and prepare for job applications.

