Prior to this pivotal work, most natural language processing (NLP) models leaned heavily on Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks to handle sequential data. While these models were effective, they often struggled with long-range dependencies and were computationally inefficient.
The Transformer model tackled these challenges head-on with a groundbreaking idea — self-attention. This innovation allowed machines to process language with an unmatched level of accuracy and speed. It signaled the dawn of a new era in deep learning, fueling everything from chatbots and search engines to AI image generators and translation systems.
If you’re intrigued by the origins of the Transformer and eager to dive into similar AI technologies, consider checking out the Artificial Intelligence Course in Noida. This comprehensive, hands-on program covers modern AI models and architectures from the ground up.
The Origins of the Transformer
Before the advent of the Transformer, NLP models primarily relied on sequential architectures like RNNs and LSTMs. These models processed data one token at a time, which made them slow and challenging to parallelize. Additionally, they often struggled to maintain context over long sequences, resulting in inaccuracies in translation and text generation.
In 2017, a team of researchers at Google, led by Ashish Vaswani, proposed a revolutionary shift — completely replacing recurrence and convolution with attention mechanisms. Their paper, “Attention Is All You Need,” introduced a fully attention-based model capable of processing words in parallel while still grasping their contextual relationships.
This innovation enabled the Transformer to:
- Train faster thanks to parallel computation.
- Manage long-range dependencies more effectively.
- Scale up to massive datasets with ease.
What’s the Transformer Architecture All About?
The Transformer is a cutting-edge deep learning model designed to handle sequential data, like text, without depending on traditional recurrence methods. Instead, it employs self-attention mechanisms to evaluate the significance of various words in a sentence, no matter where they appear.
Take this sentence, for instance:
“The cat sat on the mat because it was tired.”
The Transformer can easily grasp that “it” refers to “the cat,” even though those words are spaced apart — something that RNNs often find challenging.
Key Features of the Transformer Architecture
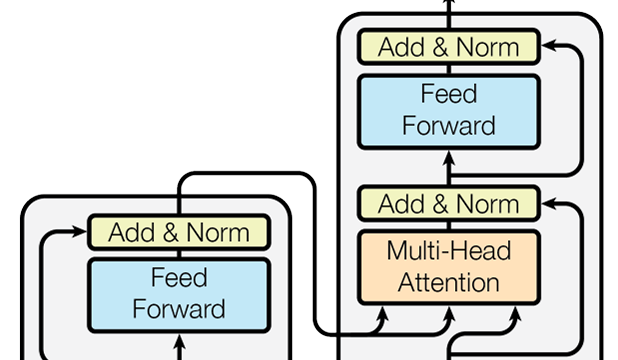
1. Encoder-Decoder Structure
This model is made up of two primary components:
- Encoder: This part reads the input sequence (like English text).
- Decoder: This part generates the output sequence (such as a French translation).
2. Self-Attention Mechanism
- This feature allows the model to assign importance scores to words based on their relationship to others in the sequence.
- For example, when processing the word “bank,” the model examines nearby words to determine if it refers to a riverbank or a financial institution.
3. Multi-Head Attention
Rather than relying on a single attention mechanism, the Transformer utilizes multiple “heads,” enabling it to focus on various contextual relationships at the same time.
4. Positional Encoding
Since Transformers don’t use sequential recurrence, positional encodings help the model grasp the order of words in a sentence.
5. Feed-Forward Networks
Each layer of the encoder and decoder includes a straightforward feed-forward network that transforms attention outputs into meaningful representations.
6. Residual Connections and Layer Normalization
These elements help stabilize training and ensure that gradients flow smoothly through deep networks.
The Self-Attention Mechanism Unpacked
At the heart of the Transformer architecture is the self-attention mechanism, which allows the model to hone in on the important words in a sentence while tuning out the less relevant ones.
Let’s break it down:
1. Each word in the input is transformed into a vector (embedding).
2. For every word, three vectors are created:
- Query (Q)
- Key (K)
- Value (V)
3. The attention score between two words is calculated using a specific formula.
Attention(Q, K, V) = softmax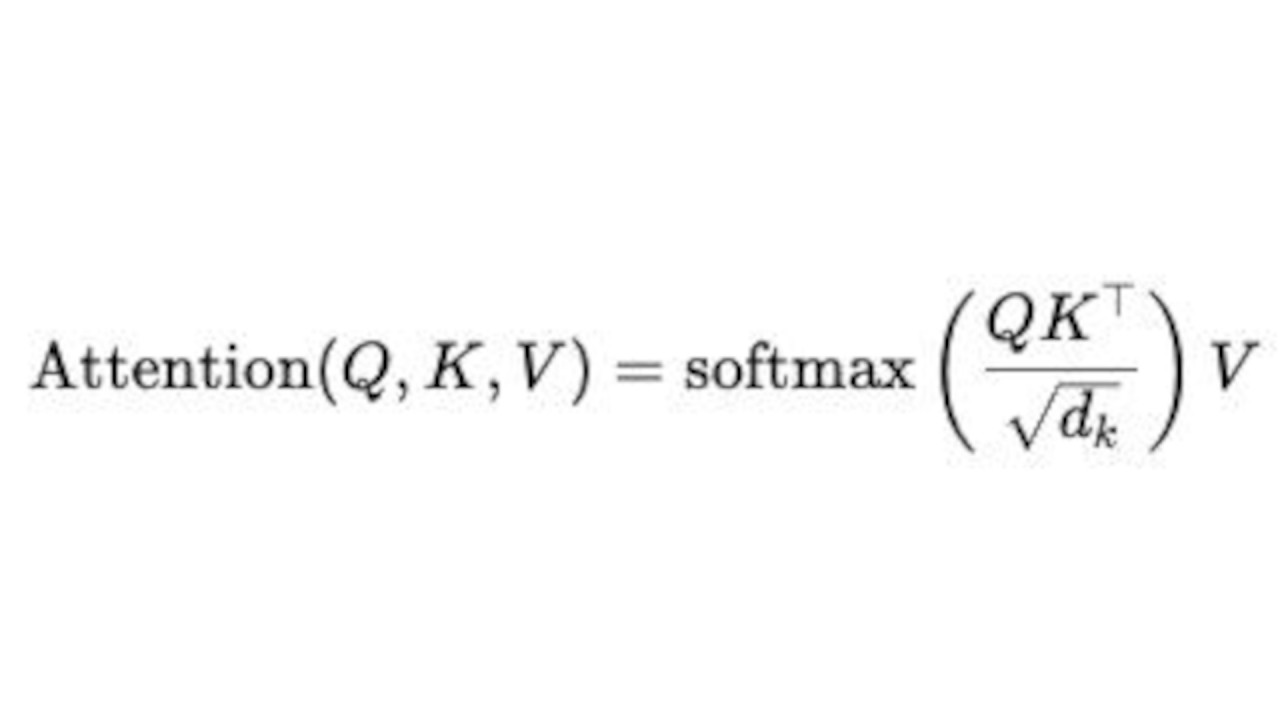 )V
)V
4. The model then combines these weighted values to create a context-aware representation for each word. This mechanism enables the model to “attend” to all other words when encoding a particular token — hence the term self-attention.
What Makes the Transformer So Effective?
The Transformer model stands out due to several key advantages:
1. Parallel Processing
Unlike RNNs, which handle one token at a time, Transformers can process all tokens at once. This parallel approach significantly cuts down on training time.
2. Handling Long-Range Dependencies
Self-attention empowers the model to link distant words and ideas effectively, making it perfect for intricate sentences or lengthy paragraphs.
3. Scalability
Transformers can easily scale with both data and computational power. This scalability has led to the development of massive models like GPT-3, PaLM, and Claude.
4. Versatility
Transformers aren’t just for text — they’re also applied in vision, audio, and multimodal AI (like generating images from text).
5. Enhanced Context Comprehension
With multi-head attention, Transformers grasp context at various semantic levels all at once — from grammar to meaning.
Architecture Overview: Encoder and Decoder
Encoder
In the original Transformer model, each of the six encoder layers is made up of:
- A multi-head self-attention mechanism.
- A feed-forward neural network.
- Residual connections along with normalization layers.
- The encoder takes the input text and transforms it into a series of encoded representations that capture its contextual meaning.
Decoder
On the other hand, each decoder layer features:
- Masked multi-head attention (which ensures it doesn’t look ahead at future tokens).
- Encoder-decoder attention (which focuses on the outputs from the encoder).
- A feed-forward layer and normalization.
- The decoder generates one word at a time, relying on the words it has already produced and the encoded input.
Mathematical Flow of the Transformer
1. Embedding + Positional Encoding
This step converts tokens into continuous vectors that include positional context.
2. Self-Attention (Encoder Side)
This mechanism captures the contextual relationships among the input tokens.
3. Encoder Output
This produces hidden states that represent the semantics of the input.
4. Decoder Masked Attention
This prevents the decoder from accessing any future information.
5. Encoder-Decoder Attention
This allows the decoder to focus on the relevant parts of the encoder's output.
6. Feed-Forward and Softmax Layers
These layers generate output tokens in a probabilistic manner until the entire sequence is completed.
Advantages of the Transformer Model
Let's dive into the advantages of the Transformer Model:
- Speed: Thanks to parallel training, it outpaces RNNs.
- Accuracy: It delivers top-notch performance in NLP tasks.
- Contextual Awareness: It understands the connections between distant words.
- Adaptability: It seamlessly works across text, images, and audio.
- Scalability: It efficiently manages billions of parameters.
Limitations of the Original Transformer
Now, onto the limitations of the original Transformer:
Even with its achievements, the original Transformer had its hurdles:
- Computational Cost: It demands a hefty amount of data and GPU power.
- Memory Usage: The self-attention mechanism grows quadratically with input length.
- Data Dependency: It requires large datasets for effective training.
- Interpretability: Figuring out attention weights can be tricky.
To tackle these challenges, innovations like Sparse Transformers, Reformer, and Longformer came into play.
Transformers in Modern AI
Today, Transformers are at the heart of almost every modern AI system:
- BERT (Bidirectional Encoder Representations from Transformers) — excels in contextual text understanding.
- GPT (Generative Pre-trained Transformer) — shines in natural text generation.
- T5 (Text-to-Text Transfer Transformer) — brings together various NLP tasks under one umbrella.
- Vision Transformers (ViT) — specialize in image classification and analysis.
- Speech Transformers — enable real-time voice synthesis and recognition.
In short, the Transformer has evolved from just a model to a foundational framework for intelligent systems.
Conclusion
The “Attention Is All You Need” paper wasn’t just a significant research achievement — it marked a true turning point in technology. It brought the Transformer architecture into the spotlight, a groundbreaking design that fundamentally changed the landscape of artificial intelligence.
By moving away from recurrence and honing in on attention mechanisms, the Transformer unlocked a level of performance, scalability, and versatility that was previously unheard of. Today, its impact reaches across text, vision, and speech, laying the groundwork for all the advanced AI systems we rely on.
For those eager to explore these revolutionary ideas further, the Artificial Intelligence Course in Noida offers a well-structured, hands-on curriculum that dives into Transformer models, attention mechanisms, and cutting-edge AI systems. It’s your gateway to mastering the technologies that are shaping the future of intelligent automation.
FAQs on “Attention Is All You Need: Landmark Transformer Paper”
Q1. What is the “Attention Is All You Need” paper?
It’s a 2017 research paper by Vaswani et al. that introduced the Transformer architecture — a model that relies entirely on attention mechanisms for processing sequences.
Q2. Why is the Transformer architecture important?
It eliminated the constraints of RNNs and LSTMs, paving the way for faster, more accurate, and scalable AI models across a variety of fields.
Q3. What is self-attention in Transformers?
Self-attention allows the model to identify which words in a sequence are most relevant to one another, enhancing its understanding of context.
Q4. How does a Transformer differ from RNNs?
Unlike RNNs that handle data one step at a time, Transformers process all words at once, which boosts efficiency and enables parallelization.
Q5. What are real-world applications of Transformers?
They’re utilized in chatbots, machine translation, image recognition, summarization, and AI assistants.
Q6. How can I learn about Transformer models in depth?
You can sign up for the Artificial Intelligence Course in Noida to gain hands-on experience in deep learning and more.