Algorithm BFS and DFS with Code
The graph traversal algorithms are the essentials of computer science as it offers systematic approaches to visiting and analyzing the interrelated data structures. The most common ones include Breadth-First Search (BFS) and Depth-First Search (DFS) with each solving graph and tree navigation problems differently. Such algorithms are required in so-called path finding, cycle detection, and connectivity analysis.
Getting to know Breadth-First Search (BFS)
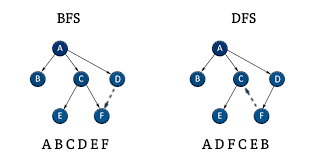
Breadth-First Search (BFS): is a graph algorithm that searches over a graph systematically visiting all the nodes of the graph in layers. It starts with a selected initial vertex (node) and examines all its adjacent nodes then adjacent nodes that are not yet visited by the graph traversal algorithm, etc. In this process every node of the current depth level is considered before moving on to nodes of the next depth level.
BFS Operation
BFS algorithm mainly employs queue data structure to store the nodes to be traversed. The queue follows a First-In, First-Out (FIFO) principle, that is in which nodes are traversed the way they were added. Like breadth first traverse (BFT), BFS also uses "visited" set/array to remember the visited vertices to avoid retraversing the nodes and entering an infinite loop.
Generally, BFS follows the following steps:
Initialization: First, choose just any vertex of a graph and put it at the end of a queue. Make this starting node as visited.
Exploration: Always take down the front element of the queue and tack him onto a been-there list.
Neighbor Discovery: Find all the adjacent nodes that you have dequeued which had never been visited.
Enqueue unvisited neighbours: Place these unvisited neighbours at the back of the queue and simultaneously mark the said neighbourhoods as visited.
Repeat: repeat the exploration and neighbor discovery steps until the queue is empty. When the graph is disconnected, then to make the graph covered we may run the BFS algorithm on each unvisited node.
Continuing on the example with vertex 0, the BFS algorithm then takes 0 (at the visited list) and its neighboring vertices and places them in the queue. Then it goes to the next element in the queue (e.g., 1) and its neighbors, and pushes the unvisited ones on the queue. It keeps on doing this until there are no nodes left in the queue, which means it has completed the traversing.
Uses of BFS
BFS is a general algorithm whose applications are many:
Unweighted Graphs: In an unweighted graph, there is a guarantee of the shortest path with BFS since it searches nodes in non-decreasing order of distance to the source.
Web Crawlers: The crawlers of the search engines apply the BFS that recursively passes all links starting with some initial page one layer at a time.
GPS Navigation Systems: BFS could be utilized in identifying the locations of all places around in GPS navigation.
Social Networking Websites: It is able to locate individuals within a specific range or degree of connections being in relation to an individual.
Broadcasting Networks: A broadcast packet within a network uses BFS so as to reach all the nodes effectively.
Garbage Collection: Garbage collection is duplicated by the algorithm given by Cheney, based on a BFS because BFS has a more favourable locality of reference.
Cycle Detection: BFS detects cycles in arbitrary undirected graphs.
Connected Components: A BFS of an undirected graph will find all connected components by searching all the vertices that can be reached from an initial starting node.
Bipartite Graph Checking: The BFS can be used to find whether a graph is bipartite or not; in other words, whether it can be painted with only two colors so that the connected vertices are not painted the same color.
Meanings of BFS: benefits and compromises
Advantages:
Guaranteed Solution: BFS will always come up with a solution; should there exist one.
Completeness: It will not end up stuck in a dead-end, or in an infinite loop, exploring every node that can be reached.
Shortest Path: It determines the shortest path in the unweighted graphs.
Easy Architecture: BFS algorithm has a simplified and trusted architecture.
Disadvantages:
Memory Consumption: BFS may also require a lot of memory depending on the size or density of the graph, as BFS must keep in memory all the nodes at the current level.
Performance: BFS may perform more slowly on large or dense graphs than performing e.g. Dijkstra because the adjacency lists may be very long.
Does not work with Weighted Graphs: BFS does not take into consideration edge weights and thus will be used to make inaccurate shortest path calculations when using weighted graphs.
What is Depth-First Search (DFS)?
Depth-First Search ( DFS ) is a more classical graph traversal algorithm exploring as deeply as possible until reaching a dead end, then later branched down. In contrast to BFS that works level by level, DFS favours depth. This method is suitable to be used, e.g. in path finding and cycle detection.
The Operations of DFS How DFS Works The way that DFS functions Safety Net Function DFS can be used in order to help rescue operations to work since DFS can take over in case a rescue mission fails.
DFS normally adopts a data structure that is stack or recursion in order to carry out its traversal approach. This is basically working down a path until no unexplored neighbors are available and then working back to see other paths. Infinite loops will be avoided by means of a set in which nodes were already visited.
Typically, the algorithm works in the following way:
Starting Point: Have a starting node you select, mark it as visited and place it in a stack.
Exploration: Remove the top occurrence of the stack and append it into the visited list.
Neighbor Discovery: Find all the neighboring vertices that have not been visited as yet.
Push Unvisited Neighbors: These unvisited neighbors are added on the top of the stack.
Backtracking: When no unexplored node is possible (adjacency list), DFS backtracks to the closest yet more distant unexplored node and does it again. This entails popping items off the stack until a node with not yet visited neighbors is reached.
Completion: Search is left to run until all the nodes are exhausted or when a certain goal is fulfilled. As in BFS, in the situation that a graph has disconnected components, one can run DFS on each unvisited node to traverse the entire graph.
As an example: using the vertex 0, DFS adds 0 to the visited list and pushes its neighbors to the list. It then goes to the element that is on the top of the stack (e.g., 1) and visits the neighbors of the element that are unexplored. This extensive search is carried out till no new unexplored nodes could be discovered after which the algorithm backtracks.
DFS Applications
The field that has wide applications of DFS is:
Path finding Algorithms: Can be used to locate the path between two vertices in a graph (maze, connected-ness of a network). It can be modified also to locate all solutions to a maze.
Topological Sorting: Topological sort is used in directed acyclic graphs (DAGs), where, in particular, it plays a major role in scheduling and dependency analysis.
Pros and cons of DFS
Advantages:
Memory requirements DFS is often more memory efficient compared to BFS since it stores only the nodes on the current path in a stack. The volume of space depends on the length of the search.
Finding Paths: In some applications, it is desirable to find a path (not necessarily the shortest one) and DFS is frequently used in that situation.
Infinite Graphs: In the case of very large or infinite graphs, DFS can be applied in a restricted depth, so DFS is more feasible than in case of BFS.
Disadvantages:
Completeness (Risk of Infinite Loops): DFS may find itself locked into infinite circuits in a graph containing cycles unless there are ways of keeping track of nodes already visited. One of those methods that could eliminate this is iterative deepening.
Not the Best Choice of Shortest Paths: DFS is not usually the shortest path in unweighted graphs as opposed to BFS.
Learning Resources: Uncodemy Tracks
Uncodemy has complete courses that one can take up to enhance their knowledge and applicative ability on algorithms such as BFS and DFS. The courses include explanations of how it works in detail, practical examples and coding exercises so learners will be able to have a good sense of how graph traversal algorithms work and when it is useful. Although particular information regarding the courses on BFS and DFS on Uncodemy were not disclosed clearly in the search results, in general, such educational websites present a structured curriculum that includes both theoretical and practical knowledge on coding. These readings are priceless to both students and professionals who would want to improve their problem-solving skills in data structures and algorithms.