Binary Search Tree (BST) Explained with Insertion and Traversal Code
Numerous methods are available for effectively storing, organizing, and retrieving data in the realm of data structures. The Binary Search Tree is one such often-used structure (BST). In the broader field of computer science, trees are crucial for efficiently and rapidly resolving issues, particularly when it comes to algorithm development. For finding, sorting, and preserving hierarchical data, the BST in particular is an essential structure that enables organized data storage and quick retrieval.
This blog offers a thorough analysis of the binary search tree. We will examine its benefits, structure, and basic functions, including insertion, traversal, searching, and deletion. We'll also include the C/C++ code implementations for each operation to help improve comprehension.
What is a Binary Search Tree (BST)
Mr. Irshad khan/ 2
days
24
14 min read
A basic data structure in computer science, a Binary Search Tree (BST) is made to keep data organized and hierarchical, such that quick lookup, insertion, and deletion operations are possible. A binary search tree follows a rigorous ordering property that controls the organization of data, in contrast to a generic binary tree, which places no restrictions on the node arrangement:
Left Subtree Property: Every value in a node's left subtree must be smaller than the value the node stores.
Right Subtree Property: In a similar vein, every value in the right subtree needs to be higher than the current node's value.
Recursive Subtree Property: The subtrees on the left and right must likewise be binary search trees. This implies that at each level of the tree, the BST property must hold recursively.
Key Characteristics of Binary Search Tree (BST)
In addition to being hierarchical structures, binary search trees include a number of inherent qualities that make them essential for algorithmic design and system effectiveness. An extensive examination of the traits that distinguish a BST is provided below:
1. Ordered Structure
The ordered structure of the binary search tree is its fundamental characteristic that sets it apart from a standard binary tree. The BST's nodes are all positioned so that:
Only nodes with values lower than the parent node are present in the left child.
Only nodes with values higher than the parent node are present in the right child.
This configuration is recursively valid for all child nodes and is constant across the tree. This implies that logarithmic time complexity is advantageous for operations like search, insertion, and deletion, provided that the BST stays balanced.
The foundation of effective binary searching is the ordered structure. Similar to how binary search works on sorted arrays, the tree methodically cuts the search space in half at each node level while looking for a certain value.
2. Uniqueness
Uniqueness of items is a requirement that is often adhered to in the majority of BST implementations. This implies that every value in the tree need to show up just once. This removes the need to take into consideration several similar values while verifying criteria, which streamlines the logic for search and traversal operations.
The BST may be expanded to handle duplicate values, though, as some real-world situations do need it. There are two typical methods for permitting duplicates:
Adding duplicate values to the left subtree is known as left-inclusive.
Duplicates are inserted into the right subtree in a right-inclusive manner.
Certain implementations even include a count with every node to record the frequency of a specific value's appearance.
Traditional BSTs function on the premise of uniqueness for simplicity and efficiency, regardless of duplicate management practices.
3. Dynamic Resizing
The dynamic nature of a BST is another noteworthy characteristic. A BST expands and contracts with ease, in contrast to arrays or static data structures that need memory reallocation or resizing:
Insertion: In order to insert a node, it must be created and positioned correctly while preserving the ordering property of the tree.
Deletion: To maintain the BST qualities, deletion eliminates a node and reorganizes the impacted area of the tree.
Because of their adaptability, BSTs are perfect for applications where data is dynamic and changes often over time. A BST can manage these activities with ease and without suffering significant performance costs, for example, if you're developing an application where users are constantly adding or removing data (such as dynamic contact lists, user logs, or real-time transaction tracking).
Additionally, unlike big preallocated arrays or fixed-size data containers, there is no wasted space because the tree grows as needed.
4. Sorted Data Access
The BST's ability to give sorted data access through an in-order traversal is a very sophisticated and practical feature.
The order of in-order traversal is as follows:
Go through the subtree on the left.
Check out the current node.
Go through the subtree on the right.
The items are automatically printed or accessed in ascending order when this traversal is done on a BST. This indicates that a BST serves as an effective in-memory sorting tool in addition to storing data.
Use Case Example: Performing an in-order traversal on your BST structure will quickly display scores in ascending order if you're managing a leaderboard with dynamically entered points.
Additionally, this characteristic provides the framework for building more intricate structures such as interval trees, priority queues, and range search applications. In-order traversals are also used by developers in algorithms that require ordered data processing, such as merging, mapping, or applying functions to ranges.
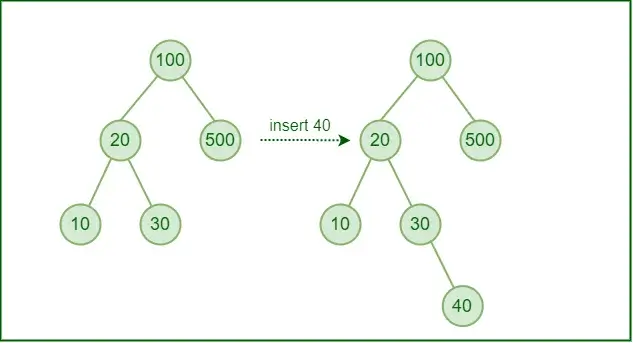
Insertion in BST
In the insertion process, the value to be inserted is compared to the value of the current node, and depending on the comparison, it is either placed in the left or right subtree.
Logic of Insertion
The new node becomes the root if the tree is empty.
Proceed to the left subtree if the value is smaller than the current node.
Go to the right subtree if the value is higher.
Continue until you find a NULL place, then add the new node there.
File Systems: Directory structures are maintained with the use of BSTs.
Memory Management: BSTs are used by operating systems for heap allocation.
Suggestions and Autocomplete: BSTs aid in storing dictionary-like information for predictive search.
Network Routing: Routing pathways are managed using BST logic.
A strong and fundamental data structure in computer science, the Binary Search Tree (BST) provides an orderly method for effectively managing, retrieving, and storing data. BSTs allow for quick operations like insertion, deletion, and search, usually in logarithmic time for balanced trees, by upholding a tight ordering where left children retain smaller values and right children carry bigger ones. Because of this, they are perfect for applications like dynamic databases, file systems, and auto-complete features that require real-time data access.
Additionally, in-order traversal produces sorted data, which increases its usefulness in situations where ordered output is required. Anyone interested in a career in software development or competitive programming must master BSTs, and structured learning via a Data Structures and Algorithms Course in Noida can provide the conceptual clarity and practical experience required to confidently take on challenging coding problems.
Placed Students
Our Clients
Partners
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and
progress tracking for optimal learning experience.