Classification algorithms in ML are the backbone of many AI systems you see around you today. From predicting whether an email is spam or not to helping doctors detect diseases early, these algorithms make data-driven decisions simple and powerful. In this article, we’ll break down classification step by step, explain the popular algorithms, and show you why they matter for real-world use.
7. Comparison of Popular Classification Algorithms
8. How to Choose the Right Classification Algorithm
9. Steps to Build a Classification Model
10. Evaluation Metrics in Classification
11. Future Trends in Classification Algorithms
12. Conclusion
13. Featured Snippet
14. FAQs
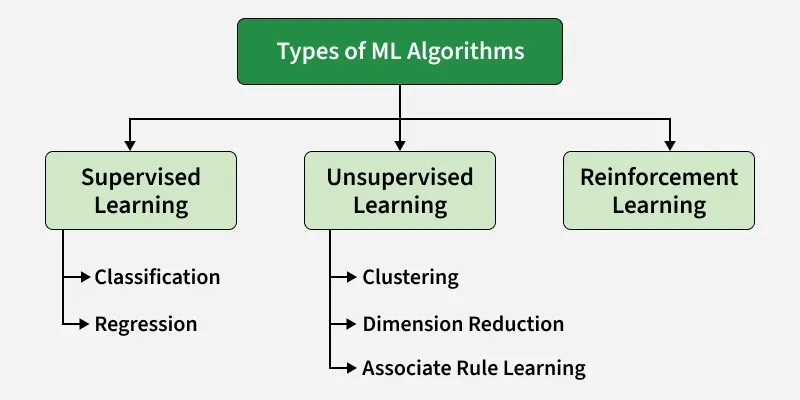
What is Classification in Machine Learning
In machine learning, classification is about sorting data into categories. Think of it like a teacher checking answer sheets and putting them into two groups – pass and fail. In the same way, ML models look at data and decide which class it belongs to.
Example: Predicting if a bank loan applicant is "high risk" or "low risk".
Another example: Checking if a photo has a cat or a dog.
Classification is different from regression because regression predicts continuous numbers, while classification predicts labels or categories.
Why Classification Algorithms Matter
Classification is at the heart of many modern technologies:
Social media platforms use it to detect fake accounts.
Banking apps use it for fraud detection.
Healthcare systems use it to classify X-rays as normal or abnormal.
➔ According to McKinsey (2023), companies that use machine learning for classification in customer analytics increase profits by 10–15% on average.
➔ In another report by Statista, the global AI market (heavily powered by classification tasks) is expected to cross $1.8 trillion by 2030.
This shows how important classification is—not just in theory, but in real business growth.
Types of Classification Algorithms
There are several algorithms you should know. Each has its own way of working and is useful for different situations.
1. Logistic Regression
Despite the name, it is used for classification, not regression.
It works well when you want to separate data into two classes, like yes/no or true/false.
Example: Predicting if a student will pass based on study hours.
2. Decision Trees
Works like a flowchart: at each step, the model asks a question and follows a path.
Easy to understand and visualize.
Example: Predicting whether someone will buy a product based on age and income.
3. Random Forest
A collection of many decision trees working together.
Reduces errors by combining multiple predictions.
Example: Used in finance for credit score predictions.
4. Support Vector Machine (SVM)
Creates a line or boundary that separates data into classes.
Works best with clear margins between categories.
Example: Used in face recognition systems.
5. Naive Bayes
Based on probability.
Works fast, especially with large text data.
Example: Spam email classification.
Real-Life Applications of Classification
Classification isn’t just theory; it powers many apps you already use:
Email filtering – Gmail uses classification to separate spam and important emails.
Medical diagnosis – Machine learning helps doctors detect diseases like cancer early.
Customer service – Chatbots classify queries to give correct responses.
Social media – Platforms use it to detect harmful content and fake news.
⮞ For students at Uncodemy, learning these algorithms is not just about coding. It’s about building real projects that companies value. For example, in Uncodemy’s Data Science course in Noida, learners practice building classification models on real datasets like healthcare or finance.
More Real-World Uses of Classification
Another powerful area where classification is widely used is e-commerce and marketing. Online stores like Amazon or Flipkart use it to recommend products by classifying customer behavior into different groups—frequent buyers, seasonal buyers, or discount-seekers. Similarly, in cybersecurity, classification models help detect unusual patterns in network traffic to stop hacking attempts in real time. In advertising, marketers use classification to segment audiences and show the right ads to the right people, improving click-through rates and reducing wasted budget. These examples prove that classification is not limited to labs—it drives everyday digital experiences we often take for granted.
Pros and Challenges of Using Classification
Pros:
Helps automate decisions.
Works with large and complex data.
Improves accuracy in predictions.
Challenges:
Requires a lot of labeled data.
Sometimes models become biased if data is not balanced.
Training complex models like SVM can take more time.
That’s why learning with hands-on guidance is important. Institutes like Uncodemy ensure you practice with real-time case studies, so you don’t just learn theory but also apply it in real jobs.
Comparison of Popular Classification Algorithms
Different algorithms shine in different situations. Here’s a simple table to help you compare:
Algorithm
Best For
Pros
Limitations
Example Use Case
Logistic Regression
Binary outcomes (yes/no)
Easy, interpretable
Not good for complex data
Predicting pass/fail
Decision Tree
Small-medium datasets
Easy to visualize
Can overfit
Loan approval
Random Forest
Large, complex data
High accuracy
Slower to train
Credit score prediction
SVM
Clear margin between classes
Works well in high dimensions
Training time is high
Face recognition
Naive Bayes
Text classification
Fast, works with large data
Assumes features independent
Spam email filter
This comparison shows why no single algorithm is perfect. The choice depends on the type of data and the problem you want to solve.
How to Choose the Right Classification Algorithm
If you’re starting your ML journey, choosing the right algorithm can feel confusing. Here’s a simple roadmap:
1. Understand your data – Is it text, images, or numbers?
2. Check data size – For small data, Decision Trees may work. For big text data, Naive Bayes shines.
3. Look at accuracy vs. speed – Random Forest gives accuracy, but Logistic Regression trains faster.
4. Think about interpretability – If you need to explain the results (like in healthcare), simple models like Logistic Regression are better.
➔ A good practice is to try multiple algorithms and then compare results. This process is called model evaluation.
Steps to Build a Classification Model
Here’s the general process you’ll follow while building classification models:
1. Collect and clean your dataset.
2. Choose your target variable (example: spam vs. not spam).
3. Split the data into training and testing sets.
4. Pick an algorithm and train the model.
5. Test it on unseen data.
6. Improve performance using tuning methods like cross-validation.
➔ In Uncodemy’s Machine Learning course in Noida, students go through these exact steps using Python libraries like Scikit-learn. This ensures they can work on real-world classification projects right after training.
Evaluation Metrics in Classification
Before we talk about future trends, it’s important to know how we measure if a classification model is doing well. These are called evaluation metrics:
Accuracy – Percentage of correct predictions.
Precision – How many of the predicted positives were correct.
Recall – How many actual positives the model successfully found.
F1-score – Balance between precision and recall.
For example, in a spam detection system, high precision means fewer important emails are wrongly marked as spam, while high recall means most spam emails are caught. Understanding these metrics helps data scientists improve models and make them more reliable in real-world use.
Future Trends in Classification Algorithms
Classification is evolving fast with new technologies:
Deep Learning – Neural networks are replacing traditional methods in areas like speech and image classification.
AutoML – Automated machine learning tools can pick the best algorithm for you.
Explainable AI (XAI) – Focus is shifting toward models that not only predict but also explain decisions clearly.
Experts believe that in the coming years, hybrid models that mix classical ML and deep learning will dominate industries like healthcare, finance, and cybersecurity.
Conclusion
Classification algorithms are one of the strongest tools in machine learning. They help in sorting data, predicting outcomes, and driving real change across industries. From logistic regression to deep learning-based classifiers, each algorithm has its role.
Featured Snippet (50–60 words)
Classification algorithms in ML are methods used to predict categories or labels, like spam vs. not spam or disease vs. healthy. Popular algorithms include Logistic Regression, Decision Trees, Random Forest, SVM, and Naive Bayes. Choosing the right one depends on your data type, size, and the balance between speed, accuracy, and interpretability.
Conclusion
Classification algorithms in ML explained in simple words show us how machines can think smartly—sorting data, predicting results, and making better decisions for industries like healthcare, finance, and even social media. From Logistic Regression to Random Forest, each method has unique strengths that open doors to real-world innovation.
At Uncodemy, you don’t just learn the theory—you practice with real projects, guided by industry experts, to become truly job-ready.
Start your machine learning journey with Uncodemy today and turn your skills into a successful career in tech.
FAQs
1. What is the main purpose of classification algorithms in ML?
Classification algorithms are used to categorize data into groups, like predicting whether a transaction is fraud or not.
2. Which classification algorithm is best for beginners?
Logistic Regression and Decision Trees are best for beginners because they are simple and easy to interpret.
3. Is Random Forest better than Decision Tree?
Yes, Random Forest usually performs better because it combines many trees, reducing errors and overfitting.
4. Where are classification algorithms used in real life?
They are used in spam filters, medical diagnosis, fraud detection, and even social media content moderation.
5. Can I learn classification algorithms without coding background?
Yes, with guided courses like those at Uncodemy, even beginners with no coding background can learn and apply classification algorithms using simple tools.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.