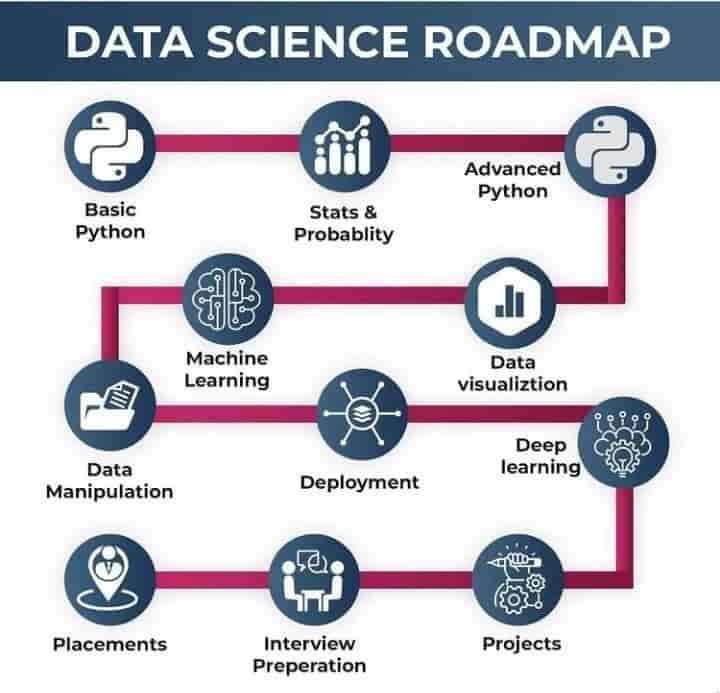
The benefit of beginning in data science early is that you can learn as fast as you like, and you can test out various tools and make errors without the risk of a professional obligation. College is the ideal playground for this. Academic projects will provide access to resources including professors, peer groups, and even online courses as well as real data. Also, you can work on examples that you know well, be it by analysing events on campus or sport performance, or trends on social media, which will make this learning process less dreadful and actually more enjoyable. This is early work that can characterise your portfolio, help you land internships and gain a stronger feeling of what roles in data science you may find most appealing.
You just need to remember that one does not have to know everything all at once. Data science is an enormous field, and even experienced professionals discover that, at any given point in their careers, they are still learning new tools and techniques. The first thing to note is to start with small steps. Go to the basics, like an introduction to statistics, a scripting language like Python or information on data visualisation. When you are more competent, you can gradually develop more advanced directions like natural language processing or machine learning.
Not only does the step-by-step method remove that feeling of overwhelm, but it also enables you to learn at a deeper level, and what can be applied.
Build the Foundations
If you are in your first year of college and curious about data science, the most important thing you should do is build a good base. Consider this step as putting the initial bricks of the house together, without having a strong foundation, the beautiful top parts will soon collapse. That foundation is math, programming and basic tools in the world of data science.
Core subjects are the first pillar. Students eagerly run to learn machine learning or artificial intelligence without understanding that such high-level subjects are deeply founded on maths. Data analysis and machine learning utilise the principles of linear algebra (vectors, matrices, etc.) in their algorithms. Statistics and probability allow you to learn about trends, test hypotheses, and generate forecasts with certainty. Although these topics might appear abstract today, they will come into focus once you begin learning how to apply them to real data. Together with math, be sure you understand computer science basics like data structures (lists, arrays, dictionaries), and how computers process and store data. These will be abilities that will facilitate your future learning.
The second pillar is the basics of programming. Python is the most suggested language to most beginners due to its simple syntax and extensive collection of data science libraries. Otherwise, R is also an excellent option, particularly when you are more oriented to statistical analysis and scholarly research. The trick is to choose one language and use it at first. Learn how to write clean code, work with variables, utilise loops and write simple functions. Your programs may be very simple when you start; the idea is simply to become confident about how to direct the computer to do exactly what you want.
Pillar three is introductory tools. They will assist you in practising your programming and math. Jupyter Notebook is an excellent Python coding environment because it lets you run pieces of code, see the output immediately, and intermix Python code with explanations and notes. Programming is somewhat more modern than tools such as Excel and Google Sheets, but these tools are incredibly helpful when you need to do quick data processing, generate graphs, and perform general analysis of tabular data. They are still popular among many professionals who use them daily to do quick tasks or use them as a first data exploration tool. The ability to filter, sort, and summarise the data in these tools will provide you with a practical advantage.
Lastly, theory itself will not train you into a data scientist, instead, you must put what you learn into practice. One of the best mini-projects that can be done at this stage is the analysis of your own class attendance vs. grades. Collect the info (per cent of attendance, and marks in individual subjects) and put them into the spreadsheet or Jupyter Notebook, and seek patterns. Are high student attendance-attaining students better? Do we have exceptions? Visualise this relation with a scatter plot or a bar diagram. Such a small exercise not only helps make your learning more interesting but also helps you learn how to take raw data and turn it into meaningful insights.
Learn Essential Data Skills
After building a strong foundation in programming and basic mathematics, the next stage in your data science journey is learning the core skills that will allow you to work with real data. Focusing on tools and techniques that will help you handle, analyse, and present information like a professional. This phase is where you begin to connect classroom learning with real-world applications.
Among the most valuable skills to acquire are data handling. Raw data is usually messy, incomplete, or even too widely spread over various sources. You must be able to clean it up, transform it, and get it prepared to be analysed. Pandas is a great Python package to handle structured data. It enables you to generate and manage tables, filter data, group items, and perform statistics using only a few lines of programming code. Another important tool is NumPy, which specialises in numerical computing. Many data science libraries depend on it and it is especially valuable in handling large amounts of data and working efficiently on mathematical calculations. In addition to them, there is SQL or Structured Query Language, which is a necessary skill, in case you want to deal with databases. It allows you to extract the precise information you require writing queries, integrating various tables, and filtering results. In combination, these three tools comprise the core of your capabilities to retrieve, analyse and synthesise data originating from virtually any source.
When you are able to work with the data then the next step is to convey your findings using data visualisation. Figures in isolation seldom do any good until they are explicitly shown. Visualisation takes raw data and converts it into charts and graphs, which can be understood easily and are more appealing to the eye. Matplotlib is a powerful Python code library that enables users to plot a wide range of plots, including line plots and intricate scatter plots. Seaborn is a Python data visualisation library that extends Matplotlib and aims to streamline the creation of attractive statistical plots. It is particularly useful in identifying patterns or trends in a set of data. Conversely, Tableau and Power BI are business intelligence packages which allow you to build interactive dashboards with minimal code.
It is vital to manage your work as your projects become more complex. This is where version control comes in. Git will enable you to track the modifications in your code so you can make test changes without the fear of loss of work. GitHub is a site to which you can upload your work, collaborate with other people on projects as well and share your project publicly. Simply gaining the rudiments of how to make changes and create branches and merge code will make you feel more competent and professional whenever you are assigned to collaborative projects.
To combine these skills, you can work on a simple yet interesting project. Get the statistics of the annual festival held in your college and include the money generated through ticket sales, the money received through sponsors, the expenditures incurred during the event and the money made on food stalls. Clean and organise the information in Pandas and SQL. Then develop transparent visualisations with Seaborn or Tableau to display the profit margins, most successful events, and the way the budget was allocated. Working on such a type of project can consolidate your technical skills, not only but also provide you with an example closer to a real-life setting to demonstrate it in your portfolio.
Explore Core Data Science Areas
Once you feel competent in the fundamentals of programming, statistics, and data handling, it is high time to enter the field and realms that make data science what it is. This is the stage where you start using your basic skills in solving more complex questions. Machine learning is one of the most significant concepts to consider. Machine learning is fundamentally the idea that we train a computer to learn from data and make predictions or decisions without explicitly programming it how to handle all situations. They begin with two main types: supervised learning and unsupervised learning. Supervised training entails training a model using labelled information, upon which the results are known beforehand. It can be applied to such tasks as estimating scores in an exam using hours of studying or categorising emails as spam or not spam. Unsupervised learning, by contrast, involves processing unlabeled data and is concerned with the process of discovery: the identification of previously unknown patterns, including clustering students by study habits.
You will also have to familiarise yourself with the necessary libraries Elements such as Scikit-learn and statsmodels, to implement these concepts. Scikit-learn is an easy-to-use but also and efficient library providing the tools to create models, and to test and evaluate them with all their usefulness and performance. When it comes to statistical analysis and testing hypotheses, Statsmodels is exceptionally useful, letting you explore the meaningful patterns of your data. These tools will not only enhance your technical skills but also show you how to analyse data and model performance critically.
Work on Projects and Portfolios
Having studied the foundational spaces of data science, the next wise step is to take up real projects that will demonstrate your competence to future employers. The worlds of practice and theory are two different things, and only practical work will teach you how to work with messy data, choose relevant models, and inform you bout your results. There are abundant datasets of very high quality on the internet. Platform competitions, like Kaggle, enable you to work on real-life problems, alongside others in the learning and professional community in nearly every country around the world. The UCI Machine Learning Repository is another goldmine of datasets, and the data category varies as it includes, but is not limited to, healthcare data and economic data. Socially relevant problems can be solved using government open data portals containing official and other freely available statistics, such as data.gov.in.
Commit your code and findings to GitHub, and spend some time making nice and straightforward README files to tell people what this project is all about, how to run it, and what difficulties you are solving or what you have to fix. The documentation used is sensible and makes people read and identify your work easily, and removes the thought that you lack the skills of professionalism. This is also a viable practice that will carry you very far in other poses that you will practice.
A smaller project that is still effective can be the examination of the sentiment on a trending topic on social media. When analysing a set of tweets or Instagram captions about a certain event, brand, or celebrity, we can tell the attitude (positive, negative, or neutral) with regard to NLP methods. Not only shall this project train you in your technical capabilities, but you will also learn about how statistics can shape real life.
What matters now is how you close the learning-doing gap at this point in the journey. The projects not only stand out in your portfolio but also provide stories that you can tell during interviews and networking events. After three years, you will want to have two or three substantial projects in your portfolio, each showing a skill or area of experience. Your demonstration of competence, creativity, and eagerness to face real-world challenges in data science will come through these projects.
Gain Practical Experience
In your third year of college, you need to go beyond theory and apply what you have learned. This is best done through internships. Internship in a startup, NGO, research lab, etc, gives you exposure to real-world data challenges, industry workflows, and team dynamics. Startups, especially, can be an excellent learning location as they frequently are in search of interns to perform small yet substantial tasks. Alternatively, NGOs and research labs can also provide chances to work with data for social good, which would add depth and significance to your portfolio. Submit your applications on a timely basis, take initiative, and turn every internship into an experience to learn as much as you can.
In case you cannot find official internships, freelance jobs, and voluntary work can prove equally good. See what you can do around your college to aid some student clubs in reviewing their event budgets, attendance trends, or survey materials. Another option you would have is to talk to local companies or societies to provide data services, like creating dashboards, analysing customer responses or providing them with a better digital presence. They are shorter-term engagements which provide you with confidence-building opportunities, some work examples to show potential recruiters, and an open avenue to how to tackle inconsistent and raw data.
Networking at this stage can lead to undercover opportunities. An optimised LinkedIn profile containing your skills, projects and interests can help facilitate easy search by recruiters and other peers. Another great opportunity to meet students with similar interests is the creation or participation in a college data science club with others and to share resources and collaborate on group projects. Both online and in-person hackathons are an excellent opportunity to train your time management skills, learn, and, occasionally, even impress recruiters. The more you immerse yourself in communities, both online and offline, the more you will understand the expectations of the field and the trends shaping it.
Prepare for the Job Market
During your last year, the emphasis is on finishing touches to your professional profile and preparing to be recruited. Technical skills matter, but employers are also interested in soft skills like communication, experience, presentation, and teamwork. The importance of being able to clearly communicate the findings of your project to a non-technical audience is paramount to building the model itself. The group work, seminars, and even informal conversations with classmates are a chance to polish these skills.
Your portfolio and resume are your personal advertising media. Make your resume short and focus on your most significant projects, internships, and skills. Make it specific to each position you are applying to, and tailor it to match the job description. The best projects should be presented in your portfolio with descriptions and clean code, where possible. You can publish your work on GitHub and even write short blog posts or case studies that can make your profile stand out to recruiters.
The last puzzle is interview preparation. On a technical role, good practice is to solve problems on sites like Leetcode to increase problem-solving speed and accuracy. To ensure that you are familiar with the format and expectations, you can review company-specific interview questions on websites such as Glassdoor. Also, prepare to discuss your projects at length, not only what you constructed, but also the reasoning behind your choices and what you learned along the way.
Conclusion
Start small, stay consistent, and keep building your skills step by step. Remember, data science is a journey, not a sprint, and every bit of progress adds up over time. Your future self will thank you for starting today.