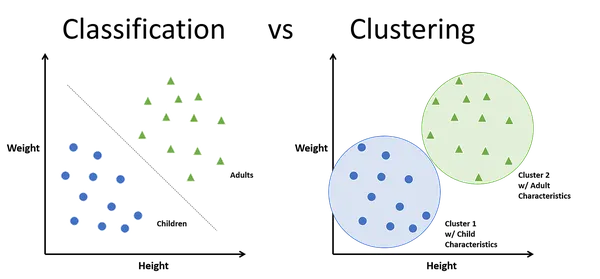
Difference between classification and clustering is one of the most common topics in data science and machine learning. If you are new to AI and analytics, these two terms might sound confusing. Both are used to group data, but the way they work is completely different. In this article, we will simplify classification and clustering, explain their differences, and give real-life examples so you can clearly understand when to use each.
3. Key Differences Between Classification and Clustering
4. Why Understanding the Difference Matters
5. Real-Life Examples of Classification and Clustering
6. Decision-Making with Classification and Clustering
7. Advantages and Limitations of Classification
Advantages
Limitations
8. Advantages and Limitations of Clustering
Advantages
Limitations
9. Use Cases in Industry
Where Classification is Used
Where Clustering is Used
10. Practical Applications of Classification and Clustering Together
11. Which One Should You Choose
12. Featured Snippet Summary
13. How Uncodemy Helps You Learn
14. FAQs
What is Classification
Classification is a supervised learning technique. This means you train a model using labeled data. Labeled data is where each data point already has a predefined category.
For example:
Emails are already marked as spam or not spam.
Students’ exam scores are labeled as pass or fail.
The model learns from these labels and then predicts the category of new, unseen data.
Features of Classification
Works with labeled data
Predicts predefined categories
Example algorithms: Decision Trees, Logistic Regression, Random Forests
Used for tasks like fraud detection, medical diagnosis, and sentiment analysis
What is Clustering
Clustering is an unsupervised learning technique. Here, the data has no predefined labels. The algorithm itself tries to group the data into clusters based on similarities.
For example:
Grouping customers into different segments based on shopping habits.
Grouping news articles based on topics, without knowing the categories beforehand.
Features of Clustering
Works with unlabeled data
Groups similar data points together
Example algorithms: K-Means, DBSCAN, Hierarchical Clustering
Used for tasks like market segmentation, image compression, and recommendation systems
Key Differences Between Classification and Clustering
Here’s a simple comparison table to understand the core differences
Feature
Classification
Clustering
Type of Learning
Supervised
Unsupervised
Data
Labeled
Unlabeled
Output
Predefined categories
Groups formed automatically
Algorithms
Decision Trees, Logistic Regression
K-Means, DBSCAN
Example
Spam email detection
Customer segmentation
Why Understanding the Difference Matters
Understanding the difference between classification and clustering is not just about theory. It has a big role in how businesses and researchers solve real problems. If a company uses the wrong method, it may waste time, money, and resources. For example, using classification when the data has no labels will give poor results, while using clustering for prediction tasks may confuse the outcome. That is why data scientists carefully choose the right technique before building a model.
In today’s world, where data is growing every second, these two methods guide smart decisions. From detecting spam emails to grouping customers, they ensure information is used in the best way. Learning the difference also builds a strong foundation for advanced machine learning. Once you are clear about classification and clustering, you can explore deeper topics like neural networks and deep learning with confidence.
Real-Life Examples of Classification and Clustering
Examples of Classification
Healthcare: Predicting whether a patient has diabetes or not based on health records.
Banking: Detecting if a transaction is fraudulent.
Education: Predicting whether a student will pass or fail based on study data.
Examples of Clustering
E-commerce: Grouping customers into categories like “budget buyers,” “frequent shoppers,” or “premium customers.”
Social Media: Grouping users based on the type of content they like.
Biology: Grouping animals based on genetic similarities.
📌 According to IBM, nearly 80% of business leaders believe data segmentation through clustering improves customer understanding
.
📌 Research by Springer shows that classification is widely used in medical imaging for disease detection and improves diagnostic accuracy.
Decision-Making with Classification and Clustering
Another way to see the difference between classification and clustering is by looking at how they are used in decision-making. Classification directly helps in making predictions where results are already defined. For instance, a bank uses classification models to decide whether to approve a loan or not. On the other hand, clustering helps in discovery. Companies often don’t know how many types of customers they have. By applying clustering, they can discover hidden customer groups and then design strategies for each.
Clustering is also valuable in research fields. For example, scientists may not know how many species of plants exist in a region. By clustering data based on physical features, new groups can be found. This is why both methods are important – one predicts based on past knowledge, and the other discovers patterns when no labels exist.
Advantages and Limitations of Classification
Advantages
High Accuracy: Since classification uses labeled data, it often provides very accurate results.
Predictive Power: Can predict outcomes in real-world scenarios like whether a loan applicant is high-risk or low-risk.
Easy to Interpret: Many classification models like Decision Trees are simple to understand.
Limitations
Needs Labeled Data: Collecting labeled data is time-consuming and expensive.
Not Flexible for Unknown Data: If new categories appear that were not in training data, the model may fail.
Bias Risk: Poor labeling or unbalanced datasets may create biased predictions.
Advantages and Limitations of Clustering
Advantages
Works Without Labels: Useful when you don’t have predefined data categories.
Discover Hidden Patterns: Can find natural groups in data you didn’t know existed.
Good for Exploration: Helps in market research and data analysis.
Limitations
No Guarantee of Accuracy: Different algorithms may create different clusters.
Hard to Evaluate: Since there are no labels, it’s tricky to measure performance.
Sensitive to Noise: Outliers in data can affect clustering results heavily.
Use Cases in Industry
Both techniques are widely used across industries. Let’s look at some real applications.
E-commerce: Customer segmentation for personalized offers.
Telecom: Grouping customers to reduce churn.
Marketing: Targeting different audience groups.
Urban Planning: Grouping regions based on income, population, or lifestyle.
Practical Applications of Classification and Clustering Together
When it comes to practical learning, both classification and clustering are often taught together because they complement each other. For example, in e-commerce, clustering can first divide customers into groups, and then classification can be applied to predict which group a new customer might belong to. This combination is powerful because it brings both discovery and prediction into one system.
Many tech companies like Amazon, Netflix, and Google use a mix of these techniques. Netflix clusters viewers into groups based on preferences and then uses classification to suggest what a particular user may like. Similarly, in fraud detection, clustering can group unusual patterns, while classification can confirm if they are truly fraud cases.
For students and professionals, learning both methods is a must in today’s data-driven world. By mastering classification and clustering, you not only understand machine learning better but also prepare yourself for real-world data challenges.
Which One Should You Choose
The choice between classification and clustering depends on your data and your goal:
If you already know the categories and have labeled data → Use Classification.
If you don’t know the categories and want to discover hidden groups → Use Clustering.
For example:
Predicting whether a transaction is fraud or not → Classification.
Grouping customers based on shopping habits → Clustering.
Featured Snippet Summary
Classification vs Clustering: Classification is a supervised learning method that uses labeled data to predict predefined categories, while clustering is an unsupervised learning method that groups unlabeled data into clusters based on similarity. Classification works well for spam detection and medical diagnosis, while clustering is best for customer segmentation and market research.
How Uncodemy Helps You Learn
At Uncodemy, you can master both classification and clustering by enrolling in our Data Science course in Delhi. The course includes hands-on training with real-world projects, supervised and unsupervised learning, and advanced machine learning algorithms. With expert mentors and career-focused learning, you’ll gain the skills companies are looking for.
Uncodemy also offers Machine Learning using Python training in Delhi, where you’ll dive deep into algorithms like K-Means, Logistic Regression, Random Forest, and more. These courses prepare you for real-world data roles and job-ready opportunities.