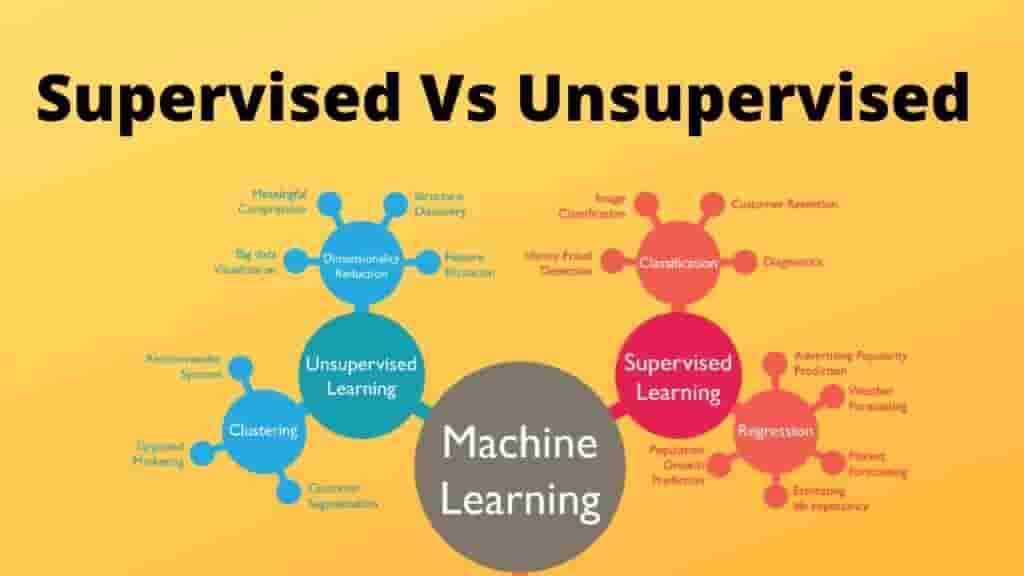
Difference between supervised and unsupervised learning
Welcome to the fascinating world of Machine Learning (ML)! If you're starting your journey, you've undoubtedly come across two foundational pillars: supervised and unsupervised learning. At first glance, these terms might sound like technical jargon, but the core concepts are surprisingly intuitive. Think of it like learning a new skill. Sometimes you have a teacher guiding you every step of the way, and other times you're left to explore and figure things out on your own. This, in essence, is the primary distinction between supervised and unsupervised learning.
Difference between supervised and unsupervised learning
Mr. Irshad3 days ago
18 comments
15 min read
In this detailed guide, we'll demystify these two approaches. We’ll break down how they work, explore their different types, look at real-world applications, and help you understand which method is right for different problems. By the end, you'll not only grasp the theoretical differences but also appreciate how these powerful techniques are transforming industries around the globe.
Supervised Learning: Learning with a Teacher
Supervised learning is the most common and straightforward type of machine learning. The "supervised" part of the name comes from the idea that the learning process is supervised by a "teacher." In this analogy, the teacher is the labeled dataset you provide to the algorithm.
How Does it Work?
Think of teaching a child to recognize fruits. You show them an apple and say, “This is an apple.” Then you point to a banana and say, “This is a banana.” By repeating this process with different fruits, the child learns to connect each fruit’s appearance with its correct name.
Supervised learning works in the same way. A machine learning algorithm is given a dataset where every example includes both the input (like an image) and the correct output label (like the fruit’s name). The algorithm’s job is to learn the relationship between inputs and outputs. It makes predictions, checks them against the correct labels, and improves its accuracy over time.
The end goal is a model that’s trained well enough to make accurate predictions on brand-new, unseen data.
Types of Supervised Learning
Supervised learning problems can be broadly categorized into two types: classification and regression.
1. Classification: Is it A or B?
Classification is used when the output variable is a category. The algorithm's task is to assign an input to one of a predefined set of classes or categories. Think of it as answering a multiple-choice question.
Email Spam Detection: One of the most classic examples. The algorithm is trained on a dataset of emails that are labeled as either 'spam' or 'not spam.' It learns the features associated with spam (like certain keywords, sender information, etc.) to classify new incoming emails.
Image Recognition: Is this picture a cat or a dog? A model is trained on thousands of images labeled as 'cat' or 'dog' to learn to distinguish between them. This extends to more complex tasks like medical imaging, where a model can be trained to classify tumors as benign or malignant.
Sentiment Analysis: Businesses use classification to determine if a customer review is positive, negative, or neutral.
2. Regression: How much or How many?
Regression is used when the output variable is a continuous, numerical value. Instead of predicting a category, the algorithm predicts a quantity. Think of it as trying to find the exact point on a line.
House Price Prediction: This is a very common regression task. A model is trained on a dataset of houses, with input features like the number of bedrooms, square footage, and location, and the output label being the final sale price. The goal is to predict the price of a new house given its features.
Stock Price Forecasting: Predicting the future price of a stock based on historical data and market trends.
Weather Forecasting: Predicting the temperature, rainfall, or humidity for a future date.
Pros and Cons of Supervised Learning
Advantages: The models are typically highly accurate and reliable because the learning process is guided by labeled data. The output is also clear and easy to interpret.
Disadvantages: The biggest challenge is the need for a large, well-labeled dataset. Creating such a dataset can be time-consuming, expensive, and require domain experts.
Unsupervised Learning: Finding Patterns on Your Own
Now, let's switch gears. What if you don't have a teacher or an answer key? This is where unsupervised learning comes in. In this approach, the algorithm is given a dataset without any explicit instructions or labels. Its task is to explore the data on its own and find meaningful structures, patterns, or groups within it.
How Does it Work?
Let's go back to our child-and-fruit analogy. This time, you don't tell the child what each fruit is. Instead, you just dump a big basket of apples, bananas, and oranges in front of them. Without any prior knowledge, the child will likely start grouping the fruits based on their inherent properties. They might put all the round, red fruits together (apples), the long, yellow ones in another pile (bananas), and the round, orange-colored ones in a third (oranges). They don't know the names "apple" or "banana," but they have identified distinct clusters in the data.
This is the essence of unsupervised learning. The algorithm sifts through unlabeled data, looking for similarities or differences to understand its underlying structure. The goal is not to predict a specific output but to gain insights from the data itself.
Types of Unsupervised Learning
Unsupervised learning is primarily used for exploratory data analysis and can be categorized into several types, with the most common being clustering and association.
1. Clustering: Grouping Similar Things Together
Clustering is the most common unsupervised learning task. It involves automatically grouping data points into clusters so that objects in the same group are more similar to each other than to those in other groups.
Customer Segmentation: Businesses use clustering to divide their customer base into distinct groups based on purchasing behavior, demographics, or browsing history. This allows them to create targeted marketing campaigns for each segment (e.g., "frequent buyers," "budget shoppers").
Genomic Analysis: Scientists use clustering to group genes with similar expression patterns, which can help in identifying the genetic basis of diseases.
Document Sorting: Grouping news articles or documents by topic without needing to pre-label them.
2. Association: Finding Relationships
Association rule mining is a technique used to discover interesting relationships between variables in a large dataset. It's about finding rules that describe how items are related.
Market Basket Analysis: The classic example is the "people who buy diapers also tend to buy beer" discovery. Supermarkets use association rules to analyze customer purchasing habits. By understanding which products are frequently bought together, they can optimize store layout, create bundled promotions, and improve product recommendations.
Recommendation Engines: While more advanced systems use a mix of techniques, association rules can form the basis of recommendation engines. For example, "Customers who watched Movie A also enjoyed Movie B."
Medical Diagnosis: Identifying which symptoms tend to co-occur can help doctors improve patient diagnosis and treatment plans.
Pros and Cons of Unsupervised Learning
Advantages: Its biggest strength is the ability to work with unlabeled data, which is far more abundant than labeled data. It's a powerful tool for exploring a dataset and discovering unexpected insights.
Disadvantages: The results can be more subjective and harder to interpret than in supervised learning. Since there's no "correct" answer, evaluating the performance of an unsupervised model can be challenging.
Key Differences at a Glance: Supervised vs. Unsupervised
Feature
Supervised Learning
Unsupervised Learning
Input Data
Labeled Data
Unlabeled Data
Primary Goal
To predict outcomes for new data
To discover hidden patterns and structures
Approach
Training with an answer key (labels)
Exploring data to find inherent groupings
Feedback
Direct feedback mechanism (is the prediction right?)
No direct feedback; based on data structure
Key Algorithms
Linear Regression, Logistic Regression, SVM, Random Forest
The choice between supervised and unsupervised learning depends entirely on your goal and, most importantly, your data.
Choose Supervised Learning if: You have a specific target you want to predict (like a price, a category, or a yes/no outcome), and you have access to a reliable, labeled dataset. If your question is "How much will this house sell for?" or "Is this email spam?", supervised learning is your go-to.
Choose Unsupervised Learning if: You want to understand the inherent structure of your data without a predefined outcome. If your question is "What are my main customer groups?" or "Are there any unusual transactions in this data?", unsupervised learning is the perfect tool for exploration and discovery.
For anyone serious about diving deep into these concepts and building practical skills, mastering both paradigms is crucial. A well-structured Uncodemy's Machine Learning course in Gurgaon provides the hands-on experience needed to tackle real-world problems, guiding you from the foundational theories of regression and clustering to building complex predictive models.
Conclusion:
Supervised and unsupervised learning aren’t rivals—they’re complementary approaches in the machine learning toolkit. Supervised learning is great for making predictions when you already know the outcome you’re targeting, while unsupervised learning is perfect for exploring data and uncovering hidden patterns you might not expect.
The key difference comes down to labels: supervised learning uses them, unsupervised learning doesn’t. Grasping this distinction is a crucial step in your machine learning journey. As data continues to expand in both volume and importance, knowing how to apply both methods will drive innovation and unlock powerful insights across industries.
Whether you’re guiding a model with an answer key or letting it explore independently, you’re tapping into the vast potential of data.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.