GANs vs Diffusion Models: Which Works Better for Images?
The world of AI-generated images has exploded over the last few years. From realistic portraits to surreal art, two families of models dominate the conversation: Generative Adversarial Networks (GANs) and Diffusion Models. If you’ve ever wondered how tools like DALL-E, Midjourney, or StyleGAN create those jaw-dropping visuals, you’re in the right place. In this blog, we’ll break down GANs and Diffusion Models in simple terms, explore their pros and cons, and help you decide which works better for your image projects.
Artificial Intelligence can now do what seemed impossible a decade ago generate high-quality, high-resolution images from scratch. This revolution started with GANs and has accelerated with Diffusion Models. Both aim to create synthetic data, but their approaches and outcomes differ significantly. Understanding these differences is crucial for developers, researchers, and creative professionals.
What are GANs?
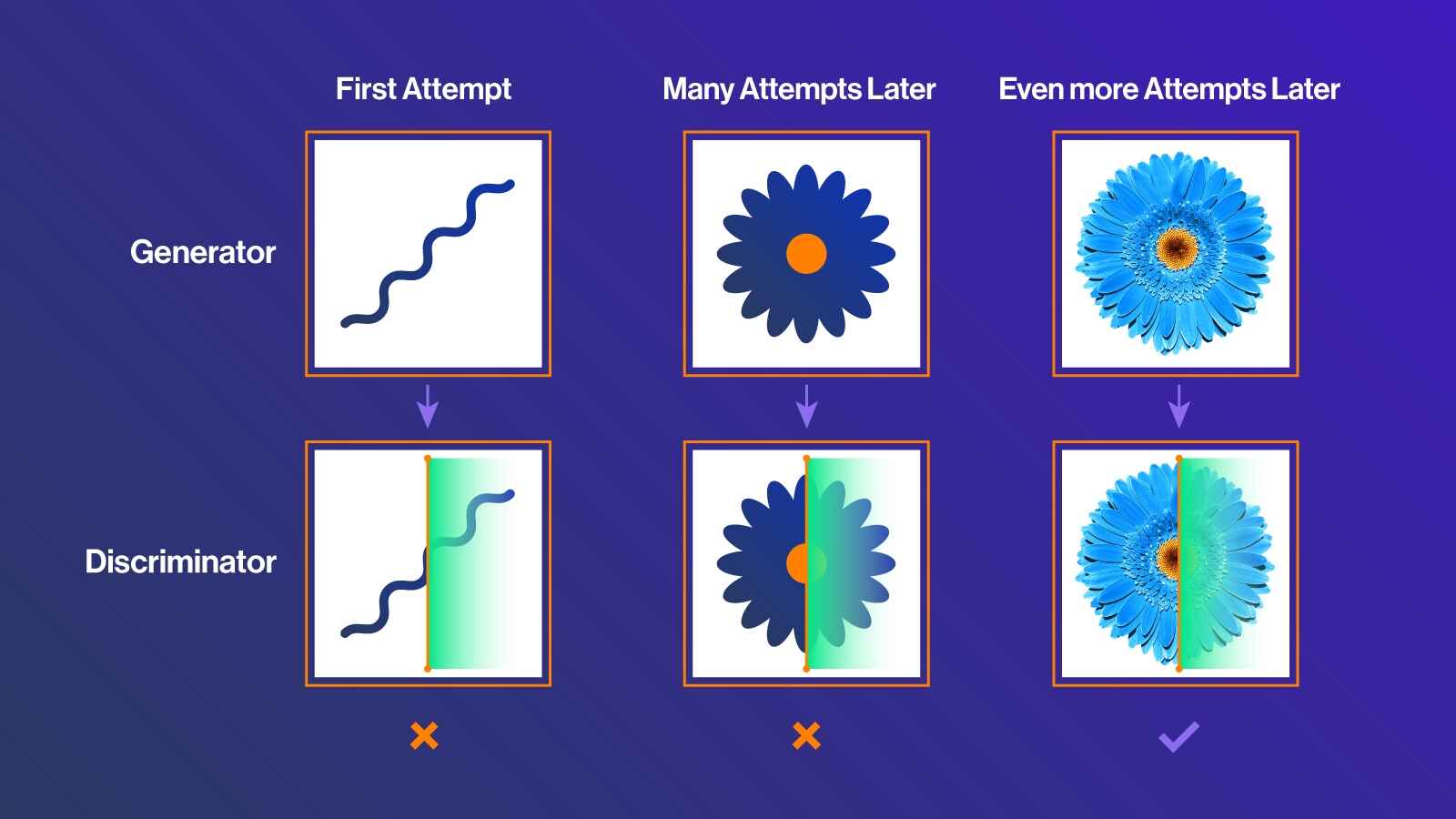
Generative Adversarial Networks (GANs) are a class of machine learning frameworks introduced by Ian Goodfellow in 2014. They consist of two neural networks:
Generator: Creates synthetic images.
Discriminator: Evaluates whether the images are real or fake.
The generator tries to fool the discriminator, while the discriminator tries to detect fakes. Over time, this adversarial “game” leads to highly realistic images.
Key Features of GANs:
Capable of producing extremely sharp and detailed images.
Can learn complex data distributions.
Widely used in face synthesis, deepfakes, style transfer, and super-resolution.
Popular GAN Variants:
DCGAN (Deep Convolutional GAN)
StyleGAN and StyleGAN2
CycleGAN for image-to-image translation
What are Diffusion Models?
Diffusion Models are a newer type of generative model that work in almost the opposite way of GANs. Instead of trying to directly generate an image, they start with random noise and gradually “denoise” it to form a high-quality image.
These models were popularized by tools like Stable Diffusion and DALL-E 2.
Key Features of Diffusion Models:
Generate very high-resolution, photo-realistic images.
More stable training than GANs.
Better at capturing diversity in outputs (less mode collapse).
1. Speed at Inference: Once trained, GANs generate images almost instantly.
2. Sharpness and Detail: Excellent at producing crisp visuals.
3. Wide Adoption: A mature technology with lots of tutorials, papers, and codebases.
Advantages of Diffusion Models
1. High-Fidelity Images: Often outperform GANs on realism and variety.
2. Stable Training: Easier to train compared to GANs.
3. Text-to-Image Power: Perfect for prompt-based generation like Midjourney or DALL-E.
Limitations of GANs
Training can be unstable and tricky.
Vulnerable to mode collapse (producing limited variety).
Harder to condition on text prompts without extra tricks.
Limitations of Diffusion Models
Slower image generation due to multiple steps.
Require large datasets and significant compute power.
Heavier models with larger storage footprints.
Which Works Better for Images?
The answer depends on your use case:
Choose GANs if you need real-time generation, sharper edges, and smaller models like in mobile apps or quick image synthesis tasks.
Choose Diffusion Models if you want state-of-the-art realism, text-prompt conditioning, or artistic flexibility even if generation takes a bit longer.
In 2025, diffusion models have become the go-to choice for text-to-image applications. However, GANs still dominate areas like super-resolution and domain-specific image tasks where speed matters.
How to Start Learning GANs and Diffusion Models
If you’re a beginner interested in image generation, here’s a roadmap:
1. Learn Python and Deep Learning Basics: Master NumPy, TensorFlow/PyTorch.
2. Start with GANs: Implement a simple DCGAN on MNIST or CIFAR-10.
3. Move to Advanced GANs: Explore StyleGAN2 and CycleGAN.
4. Dive into Diffusion Models: Learn DDPM and try out Stable Diffusion notebooks.
5. Build Projects: Text-to-image app, face editing tool, or AI art generator.
Real-World Applications of GANs and Diffusion Models
GANs: Photo enhancement, game asset generation, image-to-image translation, deepfakes.
Diffusion Models: Text-to-image generation, AI-assisted art, medical imaging synthesis, inpainting or restoring old photos.
Tips to Succeed in Generative AI
Stay updated with new papers and frameworks on arXiv.
Practice coding these models from scratch to deepen understanding.
Contribute to open-source projects like Stable Diffusion or StyleGAN implementations.
Showcase your work on GitHub or Kaggle to attract employers.
FAQs on GANs vs Diffusion Models
Q1. Are GANs outdated now that Diffusion Models exist? No. GANs are still highly relevant, especially for tasks needing fast inference and specific styles. Diffusion Models shine in prompt-based and high-fidelity tasks.
Q2. Which is easier for a beginner to learn? GANs are a good starting point due to simpler architectures. Once comfortable, you can explore Diffusion Models.
Q3. Do Diffusion Models always produce better images than GANs? Not always. They tend to produce more diverse and realistic images, but GANs can still outperform them in speed and sharpness in some scenarios.
Q4. Can I train these models on my laptop? Simple GANs can be trained on a decent GPU laptop. Diffusion Models generally need more compute or cloud resources.
Q5. Where can I learn to build these models from scratch? Uncodemy’s Artificial Intelligence & Deep Learning Course is an excellent starting point. It provides structured learning and real-world projects.
Conclusion
Both GANs and Diffusion Models have transformed how we create and manipulate images. GANs are fast and sharp, while Diffusion Models are versatile and stable. Rather than seeing them as competitors, think of them as complementary tools in your generative AI toolbox.
If you’re looking to build a career in AI-generated images, start by learning the fundamentals of both and then specialize based on your interests whether that’s lightning-fast image synthesis with GANs or cutting-edge text-to-image generation with Diffusion Models.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.