In the realm of data structures, efficiency is absolutely key. One of the most effective tools for achieving quick access, insertion, and deletion is the hash function. Whether you're building a database, a compiler, or a caching system, grasping the concept of hash functions is essential for top-notch performance. In this detailed guide, we’ll dive into what a hash function is, how it operates, the various types available, its benefits, and its real-world uses.
If you're just starting out with data structures and algorithms, it's a good idea to solidify your foundational knowledge. Consider checking out the Data Structures Course in Noida offered by Uncodemy for hands-on learning and expert guidance.
What is a Hash Function?
A hash function is a unique type of function in computing that transforms data (like strings or numbers) into a fixed-size numerical value known as a hash code or hash value. This value serves as an index for storing data in a hash table, with the main goal being to facilitate efficient data retrieval.
Key Characteristics:
- Transforms input into a fixed-size string of bytes
- Produces a number (the hash value)
- Ideally should be quick and consistent
- Aims to minimize collisions as much as possible
Why Use a Hash Function?
The primary reason for utilizing hash functions is to achieve constant-time complexity (O(1)) for search, insert, and delete operations within a hash table. Hash functions help evenly distribute data across buckets, preventing clustering and ensuring smooth performance.
Real-Life Analogy
Think of it like organizing books in a vast library, where each book is placed in a specific section based on the first letter of the author's last name. A hash function operates in a similar way—it helps you figure out where to store the data and how to retrieve it swiftly.
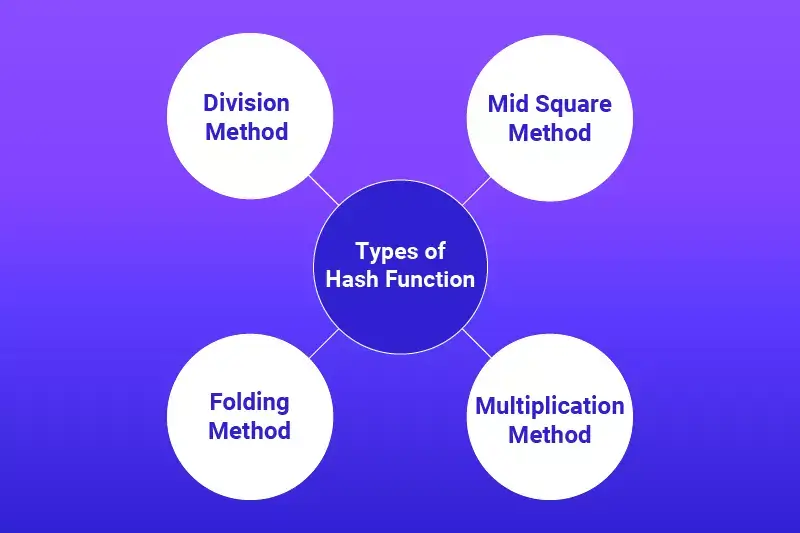
Types of Hash Functions in Data Structures
1.Division Method
This approach relies on the modulo operation:
h(k) = k mod m
- k represents the key
- m is the size of the hash table
Pros: It’s straightforward and quick.
Cons: It can be problematic if m isn’t a prime number.
2. Multiplication Method
In this method, you multiply the key by a constant (A) that falls between 0 and 1, take the fractional part, and then multiply it by the size of the table.
h(k) = ⌊m(kA mod 1)⌋
- This method tends to offer better distribution than the division method.
3. Folding Method
Here, the key is split into parts, which are then summed up to create the hash.
Use case: It’s particularly effective for keys that have a lot of digits.
4. Mid-Square Method
In this technique, you square the key and use the middle digits of the result as the hash value.
Advantage: It provides good randomness, even for keys that are quite similar.
5. Universal Hashing
This method employs a collection of hash functions and randomly picks one, which helps minimize the risk of worst-case collisions.
Collision Handling Techniques
No hash function is flawless. Occasionally, two keys end up pointing to the same index—this is what we call a collision. Let’s explore how we can tackle this issue.
1. Chaining
- Each cell in the hash table links to a list of entries.
- All items that hash to the same index are kept in this list.
2. Open Addressing
Instead of relying on lists, the table is searched linearly or quadratically for the next open slot.
- Linear Probing
- Quadratic Probing
- Double Hashing
Key Properties of a Good Hash Function
Uniformity: Ensures keys are spread out evenly
Deterministic: The same input always produces the same output
- Quick to compute
- Reduces collisions
Applications of Hash Functions
Hash functions find their way into various areas of computer science and software development:
- Hash Tables: A fundamental use in programming languages like C++, Java, and Python
- Databases: For indexing and lookups
- Cryptography: Hashing passwords with MD5 and SHA algorithms
- Caching: Utilized in systems like Memcached and Redis
- Compilers: For managing symbol tables
- Checksum Generation: To validate files and check integrity
Collision Resolution Strategies Recap
When it comes to designing or picking a good hash function, there are several key characteristics to keep in mind:
- Determinism: The same input should always produce the same hash output.
- Uniformity: It’s important that data is spread out evenly across the hash table.
- Low Collision Probability: We want to minimize the chances of two different inputs resulting in the same hash.
- Efficiency: The hash values should be computed quickly.
- Avalanche Effect: A tiny change in the input should lead to a significant change in the hash output, especially for cryptographic uses.
Collision Resolution Strategies Recap
- Chaining: Each slot in the hash table points to a linked list of entries that share the same index.
- Open Addressing (Linear/Quadratic Probing, Double Hashing): This method looks for alternative spots using a series of probing steps.
- Rehashing: If the table gets full or there are too many collisions, we increase the table size and rehash all the elements.
Load Factor and Performance
The load factor (α = n/k), where:
- n = number of elements,
- k = size of the hash table,
...is a vital performance metric. A lower load factor usually means fewer collisions, but it can also lead to wasted memory. Ideally, you want to keep the load factor below 0.7.
Hash Functions in Cybersecurity
In the realm of cybersecurity, cryptographic hash functions are a more secure type. They have some distinct features:
- Non-reversible: You can’t figure out the input just from the output.
- Tamper-Proof: Even a minor change in the input will produce a completely different output.
- Common Algorithms: MD5 (which is now considered outdated), SHA-1, and SHA-256.
These functions are commonly used for:
- Storing passwords
- Creating digital signatures
- Ensuring the integrity of blockchain data
Advantages of Hash Functions
- Quick data access and retrieval
- Efficient use of memory
- Important in cryptography for ensuring data integrity
- Helpful in load balancing and data partitioning
- Lowers the average-case time complexity to O(1)
Disadvantages of Hash Functions
- Collisions are unavoidable and must be handled
- Performance is heavily reliant on the quality of the hash function
- Open addressing can cause clustering problems
- Not ideal for retrieving ordered data
- Requires a solid understanding for effective implementation
Best Practices for Designing Hash Functions
- Use for prime number sizes for better distribution
- Steer clear of simple modulo if keys show patterns
- Implement universal hashing for unpredictable inputs
- Regularly monitor and resize the hash table to maintain performance
Hash Function vs Hash Table: Key Difference
Feature
Hash Function
Hash Table
Purpose
Maps keys to indexes
Stores key-value pairs using hash
Output
Single integer value (hash)
Structured data format
Used in
Hashing, cryptography, compression
Dictionaries, caches
Collisions
Can occur, must be handled
Impacts efficiency if frequent
Career Tip
If you're looking to break into software engineering or data science, having a strong grasp of hash functions and hash tables is absolutely essential. These concepts often pop up in technical interviews, system design questions, and backend architecture discussions.
Elevate your skills with Uncodemy’s Data Structures Course in Noida. This course provides expert guidance, hands-on projects, and support for job placements.
Summary
A hash function is a key player in the realm of data structures. Whether it’s in hash tables, compilers, cryptography, or big data systems, its significance is clear. Choosing a well-crafted hash function can lead to speedy operations and optimal memory use. Plus, by effectively managing collisions and selecting the right collision resolution methods, you can really boost your programming and system design abilities.
FAQ: Hash Function in Data Structure
Q1. What is the purpose of a hash function?
Answer: A hash function converts data into a fixed-size hash value, which helps determine where to store that data in a hash table, allowing for quick access.
Q2. How does a hash function reduce time complexity?
Answer: It enables data access through direct indexing, which typically lowers the time complexity for search, insert, and delete operations to O(1) on average.
Q3. What is a collision in hashing?
Answer: A collision occurs when two different keys generate the same hash value.
Q4. What are some common hash functions used in practice?
Answer: Commonly used hash functions include the division method, multiplication method, mid-square method, and universal hashing.
Q5. How do you resolve collisions in a hash table?
Answer: You can resolve collisions using techniques like chaining, linear probing, quadratic probing, and double hashing.
Q6. Are hash functions used in security?
Answer: Absolutely! In cryptography, hash functions are used to hash passwords and data for integrity checks, utilizing secure hash functions like SHA-256.
Q7. Can we use a hash function for sorting?
Answer: No, hash functions don’t maintain any order, so they aren’t suitable for sorting.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.