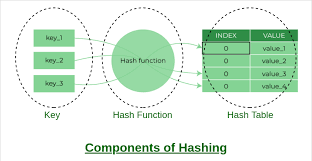
Learning about the Hash Table Concept
A hash table stores the data in such a way that values can be found quickly by a certain key. Their fundamental principle is the mapping of a key into an array index, or more simply put a hash code by a hash function. This computed index is then used to target a "bucket" or "slot" in some underlying array in which the matching value is held. The effectiveness of hash tables is the direct access to the data whose index has been calculated, and consequently its access time is much faster in comparison with linear search of array or linked lists. The average searching, inserting, and deleting the element in a hash table is O(1) in numerous cases.
Real-Life Uses of Hashing
Hashing is the process of uniquely labeling the objects in a set of similar objects.
Hashing finds application in a number of ways and examples include:
University Roll Numbers: The unique roll numbers are given to the students to access information.
Identification Numbers of Library Books: to identify location or who has borrowed the books unique numbers are assigned to the books.
In-memory tables and associative arrays: In-memory tables and associative arrays usually are implemented with hash tables, which are arrays whose indices are arbitrary strings or complex objects.
Database Indexing: They are used as disk-specialized data structures and database indexes, but are also used in this field as B-trees.
Caches: Hash tables are used in the implementation of caches, which are secondary data tables, created to speed up access to data stored in slower mediums.
Object Representation: A number of dynamic programming languages such as Perl, Python, JavaScript and Ruby use hash tables to represent objects.
Search Engines: Hash table could be used as a means of storing indexed web pages by a search engine.
Cryptography: Hash functions are commonly used in cryptography as digital signatures, data validation and data integrity.
Hash Set Vs. Hash Map
A hash table can also be Hash Set or Hash Map. The Hash Set is mainly one that stores different keys and is where the presence of an element in a collection is checked. It does not keep values with the keys. Hash Map on the other hand contains unique key-value pairs, and this enables one to retrieve a particular information using a key. Hash Sets and Hash Maps both use a hash value to calculate a hash code to store and retrieve elements directly with an average time complexity of O(1) in searching, adding and deleting.
The Hash Functions Role
An important element of a hash table is a hash function which maps the key into an array index. Hash values, hash codes, hash sums or hashes are the values created by a hash function. A hash table requires a good hash function to perform.
Good hash-function properties
In order to approach an effective hashing mechanism, a decent hash must be in a position to ascribe numerous important features:
Simple to Execute: Hash should be easy to execute and not as complex.
Uniform Distribution: It must line-up keys in a hash table evenly with the least clustering. With a non uniform distribution, collision and resolution costs increase.
Fewer Collisions: Although collisions are not avoidable, a desirable hash function should work towards reducing the number of collisions. The chance of collision may be minimized by taking prime numbers in the modulo.
Hard to Guess Key: One should find it hard to deduce the original key of any hash value.
Flexibility: The hash function must be able to adjust to modification of the hash data, e.g. difference in key size or format.
Popular Methods of hash functions
Hashing by division and hashing by multiplication are two of the most common approaches to the hash functions:
Division Hashing: In such a practice the index is computed as the remainder of a key divided by the size of the array. It is fast with prime size arrays and keys spaced equally.
As an example, index = key % array size.
Multiplication Hashing: In this method, the key has to be multiplied with a constant value between 0 and 1, the fractional portion of the product is obtained and then multiplied (by the size of the array) to obtain the index. It comes in handy when the hash table is non-prime, then there can be a uniform distribution of adjusting the constant. To add more randomness and uniform distribution Donald Knuth recommends the constant to be the golden ratio.
Collision Avoidance Methods
Collisions happen when the hash matches more than one different key to the same index. As collision is inevitable and particularly when the hash table gets filled, several methods are adopted to resolve the collision to preserve the performance. Open addressing and separate chaining are the two main implementations.
Open Hashing Separate Chaining
Open hashing Separate chaining is a popular collision resolution method. The contents of the hash table in this method are linked lists. Where a collision arises, the new element is merely inserted into the linked list at a position based on the value.
Insertion: An item is added at the beginning of the linked list with the index that is hashed.
Search: A linked list in the required index is scanned to search an element.
Deletion: It removes the element in the linked list at its hashed index.
Strengths: It is comparatively straightforward to perform in addition to being capable of dealing with an extensive number of collisions.
ocla.txt Open Addressing (Closed Hashing)
In open addressing, key-values are stored directly into the array, and a linked list is not used explicitly (see key-value pair). When a collision occurs, the system tries to find the following empty space in the table in a prescribed order. In case there is no open ability, then the key is out of table in the process of searching. The open addressing load factor cannot go beyond 1, which is bad, and as it goes close to 1, performance becomes partly destructive, therefore requiring resizing. Open addressing The maximum load factors acceptable to open addressing are 0.6 to 0.75.
Other High Tech Collision Solving Methods
However, in addition to these usual approaches, there are more sophisticated ones:
Cuckoo Hashing: Two hash tables are used and each one has its own hash function. A product may have either of these two places. When we insert them both are busy, one gets kicked out and inserted back into the alternative position in the other table and so on until there is a space. This ensures a worst-case time of look-up, a constant amortized time of insertion.
Coalesced Hashing: A technique like separate chaining and open addressing, in that the cells are not separated but open linked within the table. How collisions are resolved is by identifying the largest-indexed available empty space, placing the other colliding value in it and connecting the lengthy bucket to this newly-added slot.
Hopscotch Hashing: Hopscotch hashing is an open addressing algorithm which was developed from cuckoo hashing, linear probing and chaining. It simply makes sure that an item is either in its home bucket, or in a neighborhood of later buckets, where high throughput in concurrent setups is sought.
Dynamic Resizing, and Load Factor
Hash tables are usually dynamically resized or re-created (by this technique known as re-hashing) to contain amortized worst-case constant time insertion and lookup. One of the essential measures of a hash table is a load factor (a), i.e., ratio of the occupied entries (n) to the number of buckets (m), i.e., a=n/m.
Significance of Load Factor: If the load factor is too high, it may cause too many tables to be cluttered and too many collisions along with a longer search time. Load factor is usually controlled by software, and will be maintained at a lower fixed limit.
Resizing Process: As a load factor surpasses this maximum, the hash table tends to become increased (e.g., by doubling its flexibility), and all its present elements will be rehashed into the increased one. This re-allocation and rehashing activity can be computer expensive when performed together.
Data Structures Uncodemy Courses
Uncodemy provides stunning courses connected to data structures, one of which is about hash tables, which are aimed to improve abilities in this rather important sphere of computer science.
Algorithm/Data Structure Course in Noida: This program will give practical training of various advanced tools and technologies that are used in Data Structure and Algorithms.
Data Structure And Algorithm Course in Delhi: Like the course in Noida, hands-on training is also provided in this course and it also covers hash tables and approximation algorithms as well.
C with Data Structure Certification Training: Uncodemy also offers special courses C with Data Structure and Algorithm in Delhi. Students are required to master the basic concepts through these courses that are specially made in batches.
Data Science Certification Training: Data Science Certification Training by Uncodemy focuses on Python, Machine Learning and AI and also equips the students to take up high paying Data Science work.