Huffman Coding Algorithm: Concepts and Implementation
Mr. Irshad Khan/ 3 days ago - 15
- 11 min read
The Huffman coding algorithm showcases a special moment in computer science where mathematical beauty meets real-world usefulness. Developed by David Huffman in 1952 while he was a graduate student at MIT, this algorithm has become an essential part of data compression technology. What makes it particularly thrilling for programmers is its combination of several basic concepts: binary trees, priority queues, and greedy algorithms. Together, they create a solution that is both sound in theory and practical to implement.
The Foundation: Understanding Data Compression
Before diving deep into the Huffman coding algorithm, it's important to understand why compression matters. Every day, we produce and use large amounts of digital data, from text messages and emails to photos and videos. Without effective compression methods, our digital systems would struggle under all this information.
Traditional character encoding schemes like ASCII use a fixed number of bits for each character, usually 8 bits. While this method is straightforward and consistent, it also wastes space. For example, in most English text, the letter 'E' appears far more often than 'Z', yet both use the same amount of storage. This is where the Huffman coding algorithm stands out. It provides a variable-length encoding system that gives shorter codes to more common characters.
This method proves its worth when you look at real-world text. In English, frequent letters like 'E', 'T', 'A', 'O', and 'I' might be represented with just 2-3 bits, while less common letters like 'Q', 'X', and 'Z' might use 6-7 bits. The overall result is notable space savings, often cutting file sizes by 20-40% or more, depending on the content.
Students in Uncodemy's C programming course in Noida find that this principle goes beyond just text compression. The same basic concepts apply to image compression, audio compression, and even video compression algorithms, making the Huffman coding algorithm a key to understanding modern multimedia technologies.
How the Huffman Coding Algorithm Works
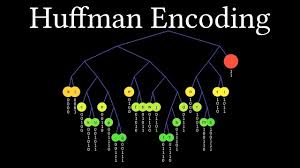
The Huffman coding algorithm works on a simple idea: create a binary tree where the path from the root to each leaf represents the code for each character. More frequent characters should have shorter paths. The algorithm follows a clear process that starts with counting character frequencies and ends with generating optimal variable-length codes.
First, it counts how often each character appears in the input data. These frequency counts are the basis for everything that comes next. The algorithm then creates a leaf node for each character, storing both the character and its frequency. These nodes go into a priority queue, sorted by frequency from lowest to highest.
This is where the interesting part begins: the algorithm repeatedly removes the two nodes with the lowest frequencies from the queue and creates a new internal node with them as children. The frequency of this new node is the sum of its children's frequencies. It then places this new node back into the priority queue. This process goes on until only one node is left—the root of the Huffman tree.
The resulting tree has a key feature: no character's code acts as a prefix for another character's code. This prefix property is important because it allows for clear decoding without needing special delimiter characters. When you move from the root to a leaf, going left may mean '0' and going right means '1,' forming a unique binary code for each character.
Students studying data structures in Uncodemy's C programming course in Noida often find this tree-building process exciting. It shows how greedy algorithms can lead to optimal solutions. The Huffman coding algorithm is greedy because it always chooses the two lowest-frequency nodes. This method still ensures a globally optimal result.
Implementation Strategies and Data Structures
Implementing the Huffman coding algorithm requires careful thought about several data structures, each playing an important role in the process. Choosing the right data structures can greatly affect the efficiency and clarity of your implementation. This makes it a great learning opportunity for students improving their programming skills.
The priority queue is essential for any efficient Huffman coding algorithm. While you could use a simple array and search repeatedly for minimum elements, a proper priority queue, often made as a binary heap, lowers the time complexity considerably. In C programming, you might implement this using a min-heap where each node contains a character and its frequency.
Binary tree representation presents another interesting challenge. Each tree node needs to store frequency information and pointers to left and right children. Leaf nodes also store the actual character being encoded. The tree structure itself acts as the encoding table. To find a character's code, you simply trace the path from the root to the leaf for that character.
Hash tables or arrays can store the final character-to-code mappings for encoding operations efficiently. Similarly, the tree structure serves as a natural decoder. You start at the root and follow the path indicated by each bit in the encoded data until you reach a leaf node, which tells you what character to output.
Memory management is especially important in Huffman coding algorithm implementations. Creating and destroying tree nodes, managing the priority queue, and handling large character frequency tables all require attention to avoid memory leaks. This reflects the type of real-world programming challenge that Uncodemy's C programming course in Noida prepares students to handle effectively.
Mathematical Properties and Optimality
One of the most impressive features of the Huffman coding algorithm is its proven guarantee of being the best solution. This isn’t just a helpful guide or a fair approximation; it is clearly the best choice for the specific problem it addresses. Understanding why this is the case offers valuable insights into designing and analyzing algorithms.
The Huffman coding algorithm creates what we call an optimal prefix code. Given a set of characters and their frequencies, no other prefix code can provide a shorter average code length. This optimality comes from the algorithm’s greedy method of always combining the two least frequent nodes, which reduces the weighted path length in the final tree.
You can calculate the average code length for a Huffman coding algorithm by adding each character's frequency multiplied by its code length. This measure directly relates to the compression ratio you will achieve. The beauty of the math lies in how the tree-building process naturally lowers this weighted sum.
Entropy theory offers the theoretical basis for understanding the limits of compression. Claude Shannon’s information theory tells us that the entropy of a message indicates the fewest bits needed to encode it. The Huffman coding algorithm usually reaches compression ratios very close to this theoretical limit, especially when character frequencies differ widely.
For students in Uncodemy's C programming course in Noida, these mathematical properties show how theoretical computer science ideas translate into real programming solutions. The Huffman coding algorithm is a great example of how solid math can improve programming effectiveness rather than make it more complex.
Real-World Applications and Variations
The influence of the Huffman coding algorithm goes far beyond academic examples; it reaches many technologies we use daily. Knowing these applications shows why learning this algorithm is important for modern programmers, no matter their area of interest.
File compression tools like ZIP and RAR use principles from the Huffman coding algorithm, even if it’s part of more complex compression methods. The DEFLATE algorithm, found in ZIP files and PNG images, combines Huffman coding with LZ77 compression to achieve great compression ratios across different data types.
Image compression formats, such as JPEG, use modified versions of the Huffman coding algorithm to compress the quantized frequency coefficients produced by discrete cosine transform operations. This application shows how the algorithm works with different types of data beyond just text.
Network protocols and data transmission systems often use Huffman-based compression to cut down on bandwidth needs. When every byte counts—like in satellite communications or mobile networks with limited capacity—the efficiency gains from using the Huffman coding algorithm become vital.
Modern versions include adaptive Huffman coding, where the algorithm updates its encoding tree as it processes data. There's also canonical Huffman coding, which offers a standard way to represent Huffman trees. This representation is especially helpful for data interchange formats.
The gaming industry also makes good use of these techniques. Game assets, from textures to audio files, often apply Huffman-based compression to lessen download sizes and speed up loading times. Understanding these applications gives students in Uncodemy's C programming course in Noida insight into how basic algorithms support the entertainment industry.
Conclusion: The Lasting Impact of Huffman Coding
The Huffman coding algorithm stands as a testament to the enduring value of fundamental computer science concepts. Developed over seventy years ago, it continues to influence modern technology in countless ways, from the files on your computer to the streaming services you enjoy. Understanding this algorithm provides insights not just into compression techniques, but into the broader principles of efficient algorithm design and implementation.
Whether you're pursuing formal education through programs like Uncodemy's C programming course in Noida or exploring these concepts independently, the Huffman coding algorithm offers an excellent balance of theoretical depth and practical applicability. The skills developed while mastering this algorithm, from data structure manipulation to algorithm analysis, form a solid foundation for tackling more advanced programming challenges.
As you continue your programming journey, remember that the huffman coding algorithm represents just one example of how mathematical insights can transform into practical solutions. The same principles of optimization, efficiency, and elegant design that make Huffman coding so effective can guide your approach to solving new problems and creating innovative software solutions.
Frequently Asked Questions (FAQs)
Q: What makes Huffman coding optimal?
A: The huffman coding algorithm produces optimal prefix codes by always combining the least frequent elements, mathematically guaranteeing the minimum average code length.
Q: Can Huffman coding work with any type of data?
A: Yes, the huffman coding algorithm can compress any data by treating it as sequences of symbols, though effectiveness varies based on data characteristics and frequency distribution.
Q: Why use variable-length codes instead of fixed-length?
A: Variable-length codes allow frequently occurring symbols to use fewer bits, significantly reducing overall file size compared to fixed-length encoding schemes.
Q: How does the decoding process work?
A: Decoding uses the same Huffman tree, starting at the root and following the path indicated by each bit until reaching a leaf node that reveals the decoded character.
Q: What are the main limitations of Huffman coding?
A: The Huffman coding algorithm requires transmitting or storing the tree structure alongside encoded data, and it may not be optimal for data with uniform character distributions.

























