Unlike traditional AI models that excel in one specific domain, multimodal AI systems can seamlessly switch between text, images, audio, video, and other data types, creating a more natural and intuitive interaction experience. This capability is transforming everything from healthcare diagnostics to creative content generation, making AI more versatile and powerful than ever before. As the demand for such advanced skills continues to grow, enrolling in an Artificial Intelligence course in Gurgaon by Uncodemy can help learners gain practical expertise in multimodal technologies and stay ahead in this rapidly evolving field.
Understanding the Fundamentals of Multimodal AI
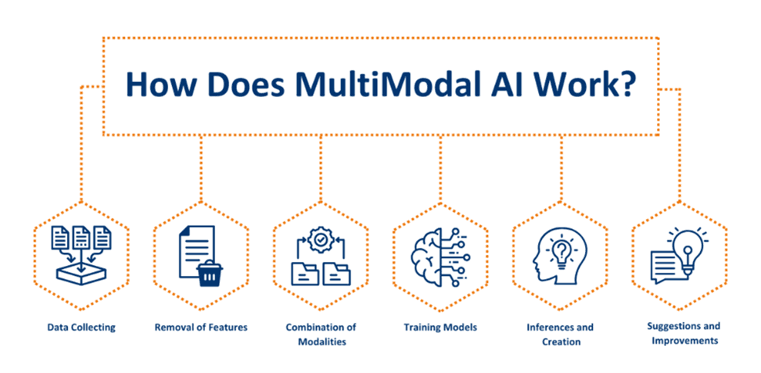
Multimodal AI models are designed to process and understand information from multiple input sources simultaneously, much like how humans naturally combine visual, auditory, and textual information to make sense of the world around them. When someone describes a scene while pointing to a photograph, humans effortlessly integrate the spoken words with the visual information to create a complete understanding. Multimodal AI systems aim to replicate this natural ability.
The foundation of multimodal AI lies in the integration of different neural network architectures, each specialized for handling specific types of data. These models typically combine convolutional neural networks for image processing, recurrent or transformer networks for text analysis, and specialized architectures for audio and video processing. The real magic happens in the fusion layers, where information from different modalities is combined to create a unified understanding.
What makes multimodal AI particularly compelling is its ability to leverage the strengths of each data type while compensating for the weaknesses of others. For instance, when analyzing a medical image, a multimodal system can combine visual features from the scan with textual information from patient records and audio notes from doctors to provide a more comprehensive diagnosis than any single-modal system could achieve.
The development of multimodal AI has been driven by advances in deep learning, increased computational power, and the availability of large-scale datasets that include multiple types of information. These technological improvements have made it possible to train models that can handle the complexity of real-world scenarios where information comes in various forms simultaneously.
The Evolution from Single-Modal to Multimodal Systems
The journey toward multimodal AI began with single-modal systems that excelled in specific domains. Early computer vision models could recognize objects in images with impressive accuracy, while natural language processing systems became increasingly sophisticated at understanding and generating text. However, these systems operated in isolation, unable to bridge the gap between different types of information.
The limitations of single-modal approaches became apparent in real-world applications where problems rarely exist in isolation. A social media platform might need to understand not just the text of a post but also the images, videos, and audio content to provide comprehensive content moderation. Similarly, autonomous vehicles must process visual data from cameras, audio information from sensors, and textual data from maps and traffic signs to navigate safely.
The breakthrough came with the development of attention mechanisms and transformer architectures that could effectively handle multiple types of input simultaneously. These advances allowed researchers to create models that could learn relationships between different modalities, understanding how text descriptions relate to images or how audio cues complement visual information.
Modern multimodal systems like GPT-4V, CLIP, and DALL-E represent the current state of the art, demonstrating remarkable abilities to understand and generate content across multiple modalities. These systems can describe images in natural language, generate images from text descriptions, and even create coherent narratives that incorporate both visual and textual elements.
How Multimodal AI Models Work
The architecture of multimodal AI models involves several key components that work together to process and integrate information from different sources. The process typically begins with specialized encoders for each modality, which convert raw input data into numerical representations that the model can work with. For images, this might involve convolutional layers that extract visual features, while text processing uses embedding layers that convert words into vector representations.
The challenge lies in aligning these different representations so that related concepts across modalities can be compared and combined effectively. This is achieved through techniques like cross-modal attention mechanisms, which allow the model to focus on relevant parts of one modality while processing another. For example, when generating a caption for an image, the model might attend to specific visual features while selecting appropriate words to describe them.
Fusion strategies represent another critical aspect of multimodal AI architecture. Early fusion approaches combine raw inputs from different modalities before processing, while late fusion methods process each modality separately and combine the results. More sophisticated approaches use intermediate fusion, where information is combined at multiple stages throughout the processing pipeline, allowing for more nuanced integration of multimodal information.
Training multimodal models requires carefully curated datasets that contain aligned examples across different modalities. These datasets must include not just isolated examples of text, images, or audio, but paired examples that demonstrate relationships between modalities. The training process involves learning these relationships while maintaining the ability to process each modality effectively on its own.
Real-World Applications Transforming Industries
The practical applications of multimodal AI are already transforming numerous industries, demonstrating the technology's potential to solve complex real-world problems. In healthcare, multimodal systems are revolutionizing diagnostic processes by combining medical images, patient histories, laboratory results, and clinical notes to provide more accurate and comprehensive assessments. These systems can identify patterns that might be missed when analyzing each data type in isolation.
The entertainment industry has embraced multimodal AI for content creation and recommendation systems. Streaming platforms use these models to analyze video content, audio tracks, and textual metadata to provide personalized recommendations that consider user preferences across multiple dimensions. Content creators are using multimodal AI to generate thumbnails, captions, and even entire video segments that align with textual descriptions or scripts.
In the automotive sector, multimodal AI is the backbone of advanced driver assistance systems and autonomous vehicles. These systems must process visual information from cameras, spatial data from lidar sensors, audio cues from the environment, and textual information from navigation systems to make split-second decisions about vehicle operation. The integration of these diverse data sources enables more robust and reliable autonomous driving capabilities.
Retail and e-commerce applications of multimodal AI include visual search capabilities that allow customers to upload images and find similar products, while also processing textual descriptions and user reviews to provide comprehensive product recommendations. These systems can understand not just what products look like but also how they are described and reviewed by other customers.
The Role of Multimodal AI in Education and Training
Educational applications of multimodal AI are particularly exciting, as they can create more engaging and effective learning experiences by incorporating multiple types of content simultaneously. These systems can generate educational materials that combine text explanations with relevant images, audio narrations, and interactive visual elements, catering to different learning styles and preferences.
Multimodal AI tutoring systems can analyze student responses across different modalities, understanding not just what students write but also how they interact with visual materials, their speech patterns during oral presentations, and their engagement levels during video-based learning. This comprehensive understanding enables more personalized and effective educational interventions.
Language learning applications particularly benefit from multimodal AI, as these systems can provide feedback on pronunciation while simultaneously analyzing written exercises and visual comprehension tasks. Students can practice conversations with AI tutors that understand both their spoken words and their gestures or facial expressions, creating more natural and immersive learning experiences.
For professionals seeking to develop expertise in this rapidly evolving field, comprehensive programs like the [Artificial Intelligence] course in Noida provide hands-on experience with multimodal AI technologies, covering both theoretical foundations and practical implementation strategies that prepare learners for the challenges of modern AI development.
Technical Challenges and Breakthrough Solutions
Developing effective multimodal AI systems presents several significant technical challenges that researchers and engineers continue to address. One of the primary difficulties lies in handling the inherent differences between modalities, including varying data formats, processing requirements, and temporal dynamics. Text data is sequential and discrete, while images are spatial and continuous, and audio data introduces temporal complexity with varying sampling rates and durations.
Alignment between modalities represents another major challenge, as corresponding elements across different data types may not have obvious relationships. Determining how specific words in a text description relate to particular regions in an image, or how audio cues correspond to visual events, requires sophisticated attention mechanisms and training strategies that can learn these relationships from data.
Computational complexity increases dramatically when processing multiple modalities simultaneously, as the model must maintain separate processing pathways while also computing cross-modal relationships. This has led to the development of more efficient architectures that can handle multimodal processing without overwhelming computational resources, including techniques like parameter sharing, attention pruning, and modality-specific optimization strategies.
Recent breakthroughs in transformer architectures have provided powerful solutions to many of these challenges. Vision transformers have unified the processing of visual and textual information, while techniques like cross-attention and multi-head attention mechanisms enable more sophisticated integration of multimodal information. These advances have made it possible to create models that can handle complex multimodal tasks with unprecedented accuracy and efficiency.
The Impact on Human-Computer Interaction
Multimodal AI is fundamentally changing how humans interact with computer systems, creating more natural and intuitive interfaces that better match human communication patterns. Traditional interfaces typically required users to interact through a single modality, typing text commands or clicking visual elements. Multimodal systems enable users to combine speech, gestures, visual cues, and textual input in ways that feel more natural and efficient.
Voice assistants enhanced with multimodal capabilities can understand not just spoken commands but also visual context from cameras and textual information from screens, enabling more sophisticated and helpful responses. Users can point to objects while asking questions, show images while requesting information, or combine speech with gesture to control smart home devices more effectively.
In professional environments, multimodal AI is enabling new forms of collaboration and productivity. Presentation software can now understand spoken narration while analyzing slide content and visual elements to provide real-time feedback and suggestions. Design tools can interpret both textual descriptions and rough sketches to generate refined visual designs, bridging the gap between creative vision and technical implementation.
The accessibility implications of multimodal AI are particularly significant, as these systems can provide alternative interaction methods for users with different abilities. Visual information can be converted to audio descriptions, speech can be translated to text, and gesture recognition can enable interaction for users who cannot use traditional input devices.
Future Directions and Emerging Trends
The future of multimodal AI promises even more sophisticated and capable systems as research continues to advance. Emerging trends include the development of models that can handle an even broader range of modalities, including tactile feedback, smell, and other sensory inputs that could create truly immersive AI experiences. These advances could enable applications in fields like robotics, where AI systems need to understand and respond to the full spectrum of sensory information.
Real-time multimodal processing represents another frontier, with researchers working to reduce latency and computational requirements so that these systems can operate in interactive applications like gaming, live translation, and real-time collaboration tools. The development of more efficient architectures and specialized hardware is making this vision increasingly achievable.
The integration of multimodal AI with other emerging technologies like augmented reality, virtual reality, and the Internet of Things is creating new possibilities for applications that were previously impossible. Smart cities could use multimodal AI to process traffic cameras, audio sensors, and textual data sources to optimize transportation systems, while healthcare applications could combine wearable sensor data with visual assessments and patient communications for continuous health monitoring.
Federated learning approaches are being developed to train multimodal models across distributed datasets while preserving privacy, enabling the development of more capable systems without centralizing sensitive data. This approach could be particularly important for applications in healthcare, finance, and other domains where data privacy is paramount.
Ethical Considerations and Responsible Development
The development and deployment of multimodal AI systems raise important ethical considerations that must be carefully addressed to ensure these technologies benefit society while minimizing potential harms. Privacy concerns are particularly significant, as multimodal systems often process highly personal information including images, voice recordings, and behavioral patterns that could be used to identify individuals or infer sensitive information.
Bias in multimodal AI systems can be particularly problematic because it can manifest across multiple dimensions simultaneously. A system that exhibits bias in image recognition might also perpetuate stereotypes in text generation, creating compounding effects that could be more harmful than bias in single-modal systems. Ensuring fairness and equity in multimodal AI requires careful attention to training data diversity and ongoing monitoring of system outputs.
The potential for misuse of multimodal AI capabilities, particularly in areas like deepfake generation and synthetic media creation, necessitates the development of robust detection and mitigation strategies. As these systems become more capable of generating realistic content across multiple modalities, the importance of digital literacy and verification tools becomes increasingly critical.
Transparency and explainability in multimodal AI systems present unique challenges, as the complex interactions between different modalities can make it difficult to understand how decisions are made. Developing interpretable multimodal AI systems that can explain their reasoning across different types of input is an active area of research with important implications for applications in healthcare, finance, and other high-stakes domains.
Preparing for a Multimodal AI Future
As multimodal AI becomes increasingly prevalent, individuals and organizations must prepare for the changes these technologies will bring. For professionals in technology fields, developing skills in multimodal AI development and deployment will become increasingly important. This includes understanding how to work with diverse data types, implement cross-modal learning algorithms, and design systems that can effectively integrate multiple forms of input.
Educational institutions are beginning to adapt their curricula to include multimodal AI concepts, recognizing that future AI professionals will need to understand how to work with systems that go beyond traditional single-modal approaches. This includes not just technical skills but also understanding the ethical implications and societal impacts of multimodal AI systems.
Organizations considering the adoption of multimodal AI should begin by identifying use cases where multiple types of input could provide value, assessing their current data infrastructure and capabilities, and developing strategies for responsible implementation. This might involve upgrading data collection and storage systems, training staff on new technologies, and establishing governance frameworks for AI deployment.
The democratization of multimodal AI tools is making these technologies accessible to a broader range of users, from content creators to small business owners. Understanding how to leverage these tools effectively while being aware of their limitations and potential risks will become an important form of digital literacy in the coming years.
Conclusion: Embracing the Multimodal Revolution
Multimodal AI represents a fundamental shift in how artificial intelligence systems understand and interact with the world, bringing us closer to AI that can truly understand and respond to the full complexity of human experience. These systems are already transforming industries from healthcare to entertainment, creating new possibilities for human-computer interaction and solving problems that were previously intractable.
The technical challenges of developing effective multimodal AI systems are significant, but ongoing research and development efforts continue to produce breakthrough solutions that make these technologies more capable and accessible. As computational power increases and algorithmic techniques improve, we can expect multimodal AI systems to become even more sophisticated and widely deployed.
The successful integration of multimodal AI into society will require careful attention to ethical considerations, responsible development practices, and ongoing dialogue between technologists, policymakers, and the public. By approaching these technologies thoughtfully and proactively addressing potential challenges, we can harness the power of multimodal AI to create a future where technology better serves human needs and capabilities.
The journey toward truly intelligent AI systems that can understand and interact with the world as naturally as humans do is still ongoing, but multimodal AI represents a crucial step forward in this evolution. As these technologies continue to mature and become more accessible, they will undoubtedly play an increasingly important role in shaping the future of human-computer interaction and artificial intelligence as a whole.