Quick Sort in Data Structure: Working and Time Complexity
Mr. Bambam Yadav / 1 days - 0
- 4 min read
Understanding Quick Sort in Data Structure
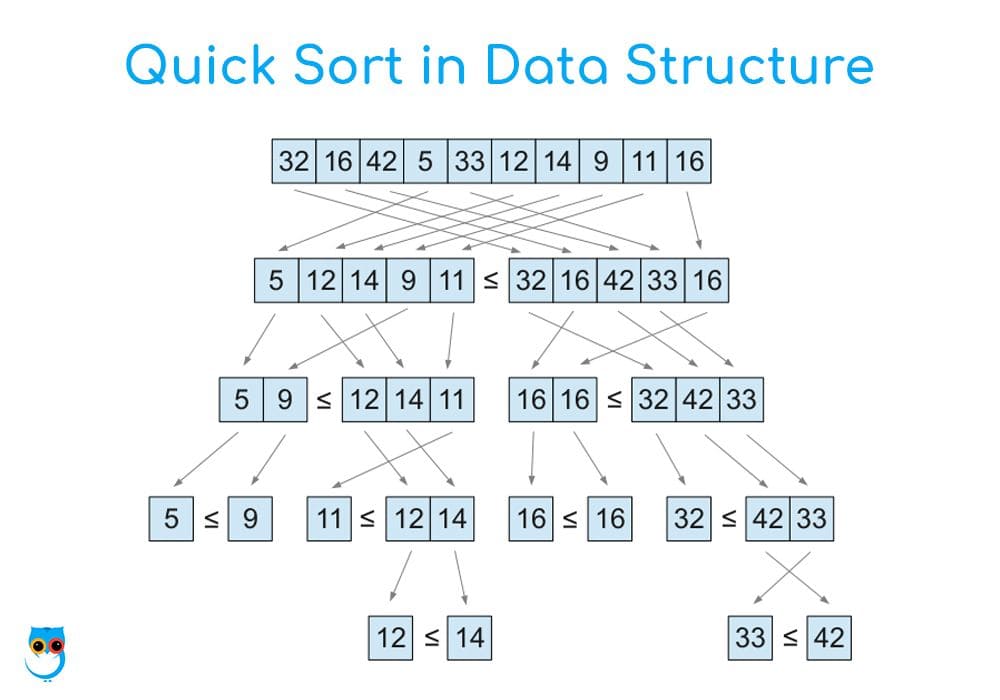
Quick Sort is a divide-and-conquer algorithm, which means it works by breaking down a big problem into smaller sub-problems, solving each of them individually, and then combining the results. The essence of Quick Sort lies in partitioningthe array and then sorting the sub-arrays.
Unlike Bubble Sort or Insertion Sort, which compare and shift adjacent elements repeatedly, Quick Sort takes a smarter approach. It selects a pivot elementand places all the elements smaller than the pivot to its left and all larger elements to its right. This step is called partitioning. Once partitioning is done, Quick Sort is applied recursively on the left and right subarrays.
Here’s a basic example to conceptualize the process:
Suppose there is an unsorted array:
[7, 2, 1, 6, 8, 5, 3, 4]
Let’s say the last element, 4, is chosen as the pivot. The algorithm rearranges the array such that all values smaller than 4 come before it and the larger values after it. After the first partition, the array might look like:
[2, 1, 3, 4, 8, 5, 7, 6]
Now, Quick Sort is applied recursively to the left ([2, 1, 3]) and right ([8, 5, 7, 6]) subarrays.
Why Quick Sort is Preferred
Quick Sort is generally faster than other simple sorting algorithms, especially for large datasets. This efficiency is one reason why it is included prominently in the 13. Data Structures Course in Noida curriculum. Some of the main reasons it is preferred are:
- Efficient for large datasets
- In-place sorting:Requires very little extra memory
- Widely used in real-world applications
Unlike Merge Sort, which uses extra space for merging, Quick Sort sorts the array in-place, saving memory. However, the efficiency of Quick Sort depends heavily on how well the pivot is chosen.
Working of Quick Sort in Data Structure
The Quick Sort algorithm involves three main steps:
- Choosing the Pivot
- Partitioning the Array
- Recursive Sorting of Subarrays
Let’s explore each step in detail.
1. Choosing the Pivot
The pivot is the element around which the array is partitioned. Choosing a good pivot is crucial. The pivot can be:
- The first element
- The last element
- A random element
- The median
The choice of pivot affects the efficiency of the algorithm. A poor pivot (like the smallest or largest element) may lead to worst-case performance.
In practice, choosing a median-of-three (median of the first, middle, and last elements) often results in better performance and is used in optimized versions of Quick Sort.
2. Partitioning the Array
Once a pivot is chosen, the next step is to rearrange the array such that:
- All elements less than the pivot are moved to the left
- All elements greater than the pivot are moved to the right
The pivot is then placed in its correct sorted position.
The partitioning process involves swapping elements to ensure this condition is satisfied. This step ensures that after one round of partitioning, the pivot is in its correct final position, and then Quick Sort is applied recursively to the subarrays on its left and right.
3. Recursive Sorting
After partitioning, Quick Sort is applied to the left and right subarrays. These subarrays are independently sorted using the same logic:
- Choose a pivot
- Partition the subarray
- Recursively sort the left and right subarrays
The recursion stops when subarrays become of size 1 or 0, as they are inherently sorted.
This recursive nature is what makes Quick Sort a divide-and-conqueralgorithm, breaking a large problem into smaller ones.
Illustration of Quick Sort in Data Structure
Let’s consider a small example step-by-step.
Array:[10, 7, 8, 9, 1, 5]
Pivot (last element): 5
Step 1: Partitioning
- Compare each element with the pivot.
- Move all smaller elements to the left.
- Resulting array: [1, 5, 8, 9, 10, 7] (pivot 5 is now in correct position).
Step 2: Recursive sorting
- Left subarray: [1] (already sorted)
- Right subarray: [8, 9, 10, 7]
Step 3: Repeat the process on [8, 9, 10, 7]
- Pivot: 7
- Rearranged: [7, 9, 10, 8] → [7, 8, 9, 10] after complete sorting.
Final sorted array: [1, 5, 7, 8, 9, 10]
Time Complexity of Quick Sort
Time complexity is a critical concept taught in any 13. Data Structures Course in Noida, and Quick Sort’s efficiency varies based on the input and pivot selection.
Let’s break it down into three cases:
1. Best Case: O(n log n)
The best-case scenario occurs when the pivot divides the array into two nearly equal halves each time. Since the array is split log n times and each level does n comparisons, the total time is O(n log n).
This is the ideal case, and it often occurs when the pivot is the median or the array is already balanced in terms of smaller and larger elements.
2. Average Case: O(n log n)
In most practical situations, even with random pivots, Quick Sort performs well. On average, the array still gets divided in a reasonably balanced way, so the average time complexity also becomes O(n log n).
This makes Quick Sort more efficient than Bubble Sort or Selection Sort, whose average time is O(n²).
3. Worst Case: O(n²)
The worst-case occurs when the pivot is always the smallest or largest element. In such cases, one side of the partition ends up being of size n-1, and the other is empty. This leads to n levels of recursion and n comparisons at each level, giving O(n²) time.
Worst-case happens when the array is already sorted or reverse sorted and the pivot is poorly chosen (e.g., always the last element).
Space Complexity
Despite its recursive nature, Quick Sort is an in-place sorting algorithm, which means it doesn’t use additional arrays for sorting. The only space used is for the recursive call stack.
- Average and Best Case Space Complexity: O(log n)
- Worst Case Space Complexity:O(n) (due to unbalanced recursion)
Stability of Quick Sort
Quick Sort is not a stable sorting algorithm. Stability in sorting means that two equal elements retain their original order after sorting. Since Quick Sort may swap elements far apart, the original order may not be preserved.
However, in many applications, stability is not essential. In those where it is, Merge Sort or a modified version of Quick Sort is preferred.
Quick Sort vs. Other Sorting Algorithms
Students of the 13. Data Structures Course in Noidaoften compare various algorithms to understand their use cases better. Here’s a basic comparison:
| Algorithm | Time Complexity (Average) | Stability | Space |
|---|
| Quick Sort | O(n log n) | No | O(log n) |
| Merge Sort | O(n log n) | Yes | O(n) |
| Bubble Sort | O(n²) | Yes | O(1) |
| Insertion Sort | O(n²) | Yes | O(1) |
Quick Sort is ideal for large datasets when memory is limited and stability is not required.
Real-World Applications of Quick Sort
Quick Sort is not just a theoretical concept—it is used widely in real-life applications, including:
- Internal implementation of sorting functions in programming libraries
- Database systems where in-place sorting is needed
- Embedded systemswhere memory usage needs to be minimized
- Gaming applications for sorting scores, objects, or rendering
It is also commonly taught and used in competitive programming due to its speed and simplicity.
Conclusion
Quick Sort remains one of the most powerful sorting techniques in computer science. Its balance of speed and memory efficiency makes it a go-to choice for many applications. By dividing the problem into manageable parts, using smart partitioning, and reducing memory usage, Quick Sort provides an ideal example of how theoretical algorithms solve practical problems.
For students enrolled in a 13. Data Structures Course in Noida, understanding the working of Quick Sort in data structureis essential. It forms the foundation of not just sorting problems but also builds logic for more advanced algorithms in search, divide-and-conquer strategies, and optimization problems.
By focusing on clear concepts like partitioning, pivot selection, and recursion, and analyzing performance in various scenarios, learners can gain both academic and practical mastery over this important algorithm. Mastery over such algorithms also lays the groundwork for acing coding interviews and competitive programming contests.

























