RNNs in Deep Learning: Working with Sequential Data
In the realm of artificial intelligence (AI) and deep learning, data comes in all sorts of shapes and sizes. Some data, like images, can be tackled as standalone pieces, while other types need a model that understands order and sequence. That’s where Recurrent Neural Networks (RNNs) step in.
RNNs are crafted specifically for handling sequential data, which includes time series, speech, natural language, and sensor data. Their unique ability to “remember” previous information and leverage it for predictions makes them a standout architecture in the deep learning landscape.
In this article, we’ll dive into RNNs in Deep Learning: Working with Sequential Data, discussing their significance, architecture, real-world applications, and how they stack up against newer models like LSTMs and GRUs. For anyone looking to specialize in AI, getting a solid grasp of RNNs is crucial, and enrolling in structured training programs like the Artificial Intelligence Course in Noida can set you on the right path.
What are RNNs?
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to work with sequential data. Unlike traditional feedforward neural networks, RNNs have connections that create directed cycles, enabling them to keep a memory of past inputs. This feature is vital for tasks where the order of inputs is significant.
For example, when predicting the next word in a sentence, the meaning hinges on the words that came before it. Standard networks would treat each word in isolation, but RNNs can draw on previous context to enhance their predictions.
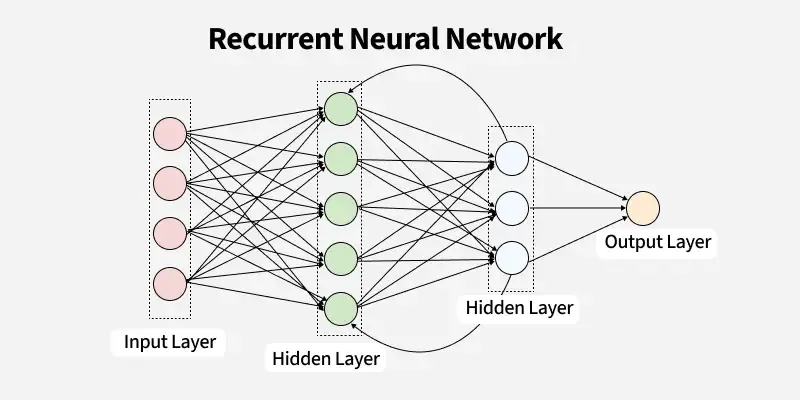
Architecture of RNNs
The architecture of RNNs has a unique twist compared to traditional feedforward neural networks.
- Input Layer: Here, sequential data is introduced one step at a time, like the words in a sentence.
- Hidden Layer with Loops: What sets RNNs apart is that their hidden layers can send information not just forward but also loop back to themselves, creating that all-important “memory” effect.
- Output Layer: This layer then generates results based on the entire sequence it has processed.
- -Sequential Processing – RNNs are designed to process data one step at a time, making them perfect for text, speech, and time-series challenges.
- -Context Awareness – They can hold onto past information, which is essential for grasping context, especially in natural language processing.
- -Versatility – RNNs find applications across various fields, from financial forecasting to healthcare diagnostics.
- -Foundation for Advanced Models – Many sophisticated architectures like LSTMs and GRUs build upon the principles established by RNNs.
Challenges with RNNs
While RNNs are quite powerful, they do come with their own set of challenges:
- Vanishing Gradient Problem – As sequences get longer, gradients tend to shrink, making it tough for RNNs to grasp long-term dependencies.
- Exploding Gradient Problem – On the flip side, sometimes gradients can blow up, resulting in unstable models.
- Training Complexity – RNNs generally require more time to train compared to simpler feedforward networks.
These hurdles have spurred the creation of more advanced variations like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU).
Advanced RNN Architectures
1. Long Short-Term Memory (LSTM)
LSTMs are crafted to tackle the vanishing gradient issue by employing gates that manage the flow of information. They excel at learning long-term dependencies.
2. Gated Recurrent Unit (GRU)
GRUs streamline LSTMs by merging the forget and input gates into a single update gate. This makes them quicker to train while still addressing gradient problems.
3. Bidirectional RNNs
These networks analyze data in both forward and backward directions, which is particularly beneficial for tasks like speech recognition, where understanding context from both the past and future enhances accuracy.
Applications of RNNs in Real Life
1. Natural Language Processing (NLP)
- Sentiment analysis
- Machine translation
- Chatbots and virtual assistants
2. Speech Recognition
- Voice-to-text applications
- Virtual assistants like Siri and Alexa
3. Healthcare
- Predicting patient health records over time
- Diagnosing based on sequential medical data
4. Finance
- Stock market prediction
- Fraud detection in transactions
5. Music and Text Generation
- Composing new music
- Generating text such as articles or poetry
RNNs vs. Other Models
Feature
RNNs
LSTMs
GRUs
Transformers
Handles sequential data
Yes
Yes
Yes
Yes
Long-term memory
Weak
Strong
Strong
Strongest
Training speed
Moderate
Slow
Faster than LSTM
Fast with large data
Use cases
Basic sequence tasks
Complex sequence tasks
Efficient alternatives
State-of-the-art NLP
Why Should You Learn RNNs Today?
Even though Transformers are all the rage right now, RNNs still hold a crucial place in the world of machine learning. They provide a solid foundation for understanding how sequential data is handled, and many practical applications still depend on them because they’re straightforward and efficient, especially with smaller datasets.
For those looking to carve out a career in AI, starting with RNNs and then progressing to LSTMs, GRUs, and Transformers can really solidify your understanding. Programs like the Artificial Intelligence Course inNoida are designed to give learners a hands-on approach to these concepts.
Career Opportunities with RNNs
Getting a grip on RNNs and sequential data can open up a variety of career options:
- Machine Learning Engineer
- NLP Engineer
- AI Research Scientist
- Data Scientist
- Speech Recognition Specialist
- Financial Data Analyst
As AI continues to grow, there’s a rising demand for professionals who are well-versed in sequential models across various industries.
The Future of RNNs in Deep Learning
While Transformers may be leading the charge in current research, RNNs will still be essential for tasks that involve smaller datasets, edge devices, and real-time predictions. They serve as a crucial stepping stone for grasping more advanced architectures, making them a must-learn in deep learning education.
Conclusion
Recurrent Neural Networks (RNNs) are still a key player in the world of deep learning, especially when it comes to working with sequential data. They’re the driving force behind many applications in natural language processing, speech recognition, finance, and healthcare. Although they do encounter some hurdles, like the vanishing gradient problem, their more advanced counterparts—LSTMs and GRUs—have made them suitable for tackling more intricate tasks.
For those looking to break into this field, mastering RNNs is about more than just one model; it’s about laying a solid groundwork for all sequence-based AI architectures, including the cutting-edge Transformers. If you’re eager to dive into this exciting area, consider enrolling in structured programs like the Artificial Intelligence Course in Noida. These programs offer hands-on experience, real-world projects, and placement support to help you thrive in your AI career.
FAQs on RNNs in Deep Learning: Working with Sequential Data
Q1. What are RNNs used for in deep learning?
RNNs are mainly utilized for tasks involving sequential data, such as speech recognition, text generation, machine translation, and financial forecasting.
Q2. What’s the difference between RNN, LSTM, and GRU?
RNNs serve as the foundational model but can struggle with long-term dependencies. LSTMs incorporate gates to manage long-term memory, while GRUs streamline LSTMs for quicker training.
Q3. Do companies still use RNNs in AI projects?
Absolutely! RNNs continue to be employed in various practical projects, particularly with smaller datasets and real-time applications, even though Transformers are more prevalent in large-scale NLP.
Q4. Can beginners start with RNNs before moving on to LSTMs and Transformers?
Definitely! RNNs are more straightforward to grasp and provide a conceptual base for understanding advanced models like LSTMs, GRUs, and Transformers.
Q5. How do I begin learning RNNs and sequential models?
Start by getting a handle on the basics of deep learning, then delve into RNNs, followed by LSTMs and GRUs. Joining professional training programs like the Artificial Intelligence Course in Noida (Uncodemy.com) can speed up your learning with expert guidance and hands-on projects.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.