In this article, we’ll dive into the inner workings of Seq2Seq models, their structure, real-world uses, and how they’ve evolved to influence the future of Natural Language Processing (NLP). Whether you’re a student, a data scientist, or a professional delving into AI solutions, getting to know Seq2Seq models will enhance your understanding of today’s language generation technologies.
If you’re eager to learn how models like Seq2Seq, Transformers, and RNNs operate in real life, signing up for an Artificial Intelligence Course in Noida could be a fantastic starting point. This course offers expert guidance and hands-on experience with the latest NLP techniques.
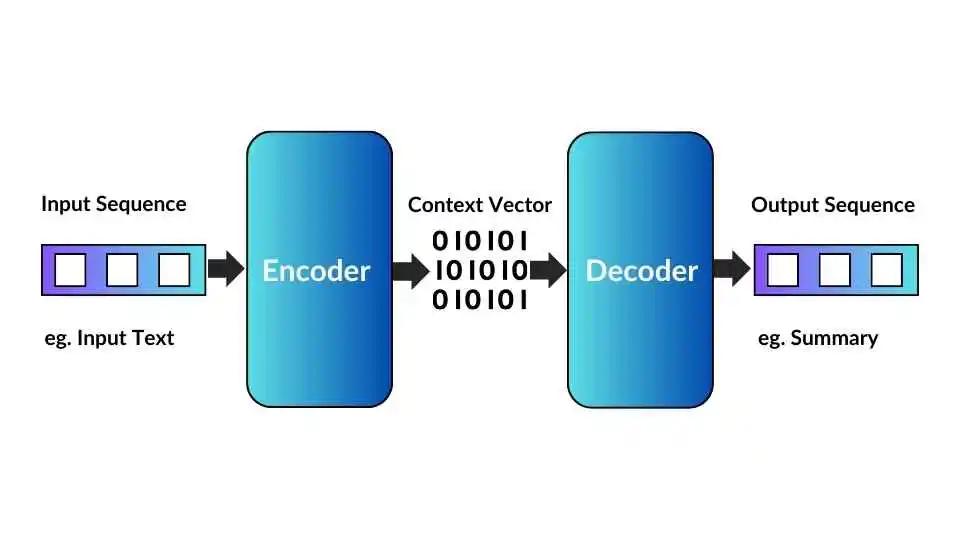
What Are Seq2Seq Models?
Seq2Seq (Sequence-to-Sequence) models are a type of deep learning model that converts one sequence of elements into another. Initially designed for machine translation (like translating English to French), these models are now widely applied across various NLP tasks.
A Seq2Seq model takes an input sequence (such as a sentence in English) and produces another sequence (like its French translation). The concept is straightforward yet powerful: encode the input information into a fixed representation and then decode it to generate the desired output.
At its core, a Seq2Seq model consists of two main parts:
- Encoder: This component processes the input sequence and transforms it into a fixed-length context vector.
- Decoder: This part takes that context vector and generates the output sequence step by step.
The Architecture of Seq2Seq Models
1. Encoder
The encoder is like the brain of the operation, tasked with reading and grasping the entire input sequence. It's usually built using Recurrent Neural Networks (RNNs), LSTMs (Long Short-Term Memory), or GRUs (Gated Recurrent Units), processing each word in the input one after the other.
For example, if the input is “I am learning AI,” the encoder will take in each word and create a series of hidden states. The last hidden state is referred to as the context vector, which neatly summarizes all the information from the input sentence.
2. Context Vector
Think of the context vector as a bridge connecting the encoder and decoder. It’s a fixed-length vector that captures a condensed version of the input sequence. However, in traditional Seq2Seq models, this context vector can become a bit of a bottleneck for longer sentences since it has to cram all the information into a single vector.
This challenge led to the development of attention mechanisms, which we’ll dive into later.
3. Decoder
The decoder is responsible for generating the output sequence based on the context vector. It predicts one word at a time, using its previous predictions to inform the next step. For instance, if the task is translation and the model has produced “Je,” it will then use that output to predict the next word “suis,” and continue from there.
Just like the encoder, the decoder is also implemented using RNN, LSTM, or GRU layers.
How Seq2Seq Models Work (Step-by-Step)
Let’s simplify the sequence-to-sequence process into easy-to-follow steps:
1. Input Processing:
First, the input sentence gets tokenized and transformed into embeddings, which are just numerical representations of the words.
2. Encoding:
Next, the encoder takes each word and creates hidden states. The last hidden state is then passed to the decoder as the context vector.
3. Decoding:
The decoder uses this context vector to generate the first word of the output sequence.
4. Feedback Loop:
Once a word is predicted, it’s fed back into the decoder to help predict the next word, and this continues until the sentence is complete.
5. Output Sequence:
In the end, you get a coherent sequence that matches the input, whether it’s a translation, summary, or response.
Limitations of Basic Seq2Seq Models
Even though Seq2Seq models were groundbreaking, they do have some drawbacks:
1. Loss of Context: For longer sentences, the fixed-length context vector struggles to keep all the input information intact.
2. Difficulty in Long-Term Dependencies: Traditional RNNs have a tough time managing long dependencies effectively.
3. Sequential Processing: RNN-based Seq2Seq models process tokens one at a time, which slows down both training and inference.
To tackle these challenges, researchers came up with attention mechanisms, and later, Transformer architectures, which have transformed the field of NLP.
The Evolution: Seq2Seq with Attention
The introduction of the attention mechanism was a game-changer that tackled the main limitations of Seq2Seq models. Instead of depending on a single fixed context vector, attention enables the decoder to “look back” at the encoder’s outputs during each decoding step.
Here’s how it works:
- The decoder doesn’t rely on just one context vector; it calculates weighted averages of all the encoder’s hidden states.
- These weights help determine which parts of the input are most relevant for generating the current output word.
So, if the model is translating “The cat is on the mat,” it can focus on “cat” when generating “chat” in French, rather than trying to compress the entire sentence into a single context.
Applications of Seq2Seq Models
Seq2Seq models play a crucial role in various AI and NLP tasks. Let’s dive into some of their key applications:
1. Machine Translation
Seq2Seq models made their debut in machine translation, particularly in Google’s neural machine translation systems. They excel at translating entire sentences from one language to another while keeping the context and grammar intact.
2. Text Summarization
This task involves the model taking a lengthy document and distilling it into a concise summary without losing the essential meaning. The encoder processes the full text, and then the decoder crafts a shorter version.
3. Chatbots and Conversational AI
Today’s chatbots heavily depend on Seq2Seq architectures to generate relevant responses to user inquiries. For instance, if you ask, “What’s the weather today?”, the model might respond with, “It’s sunny with a light breeze.”
4. Speech Recognition
Seq2Seq models are also utilized to transform spoken audio into text transcriptions. The input consists of a series of acoustic signals, and the output is the corresponding text.
5. Question Answering Systems
In AI-driven search engines and enterprise chatbots, Seq2Seq models can comprehend a user’s question and generate precise answers based on the context.
6. Code Generation
Seq2Seq models even facilitate the conversion of natural language instructions into executable code, forming the backbone of tools like GitHub Copilot and AI-assisted coding environments.
Seq2Seq vs. Transformer Models
While Seq2Seq models based on RNNs and LSTMs were once the go-to, Transformer models (like T5, BERT, and GPT) have now taken the lead due to their enhanced efficiency and accuracy.
Transformers replaced the recurrence approach with self-attention mechanisms, enabling models to process entire sequences simultaneously. This shift makes them significantly faster and better equipped to manage long-range dependencies.
Nonetheless, Seq2Seq remains the conceptual bedrock of all modern Transformer-based architectures. Models like T5 (Text-to-Text Transfer Transformer) have directly evolved from the Seq2Seq framework, reshaping text generation tasks.
Advantages of Seq2Seq Models
When it comes to Seq2Seq models, there are some clear advantages to consider:
- They can manage input and output sequences of varying lengths.
- They're adaptable for a range of NLP tasks.
- With the addition of attention mechanisms, their performance can really shine.
- They excel at grasping contextual representations, even with smaller datasets.
Disadvantages of Seq2Seq Models
However, there are also some drawbacks:
- They often struggle with long-term dependencies.
- Inference can be slow because they generate tokens one at a time.
- The fixed context vector can lead to some loss of information.
- Training requires a hefty amount of labeled data.
Future of Seq2Seq Models
Looking ahead, while Transformer-based architectures are currently leading the way in NLP, Seq2Seq models still play a crucial role in education and conceptual understanding of text generation. Many of the latest models, like T5, BART, and GPT, are built on the Seq2Seq framework but come with significant enhancements.
As research progresses, there's a growing interest in hybrid models that blend Seq2Seq and Transformer concepts to improve context awareness, speed, and overall efficiency.
Conclusion
In conclusion, the Seq2Seq model has truly transformed the landscape of Natural Language Processing (NLP). From machine translation to summarization and dialogue systems, it has set the stage for how AI comprehends and generates text.
By getting a solid grasp of Seq2Seq principles, you'll have a clearer insight into the evolution of modern models like GPT and T5. If you're keen on deepening your knowledge in this field, think about signing up for an Artificial Intelligence Course in Noida — a thorough program aimed at teaching you deep learning, NLP, and practical AI applications.
FAQs on Seq2Seq Models in AI
Q1. What exactly is a Seq2Seq model in AI?
A Seq2Seq model is a type of neural network designed to convert one sequence into another. This can be anything from translating text to summarizing information.
Q2. What’s the biggest drawback of Seq2Seq models?
The main drawback is that they rely on a fixed-length context vector, which can make it tough to handle longer input sequences effectively.
Q3. How does the attention mechanism enhance Seq2Seq models?
The attention mechanism lets the decoder concentrate on specific parts of the input sequence during each decoding step, which boosts accuracy and helps retain context.
Q4. Are Seq2Seq models still relevant today?
Absolutely! While they've mostly been overshadowed by Transformer architectures, Seq2Seq models are still quite useful in smaller or specialized NLP applications.
Q5. What skills should I focus on to work with Seq2Seq models?
You’ll want to get comfortable with Python, TensorFlow or PyTorch, and deep learning concepts like RNNs, LSTMs, and attention mechanisms.
Q6. How can I kickstart my learning about Seq2Seq and NLP models?
A great way to start is by diving into practical training and guided projects in an Artificial Intelligence Course in Noida, where you’ll gain hands-on experience with the latest NLP models.