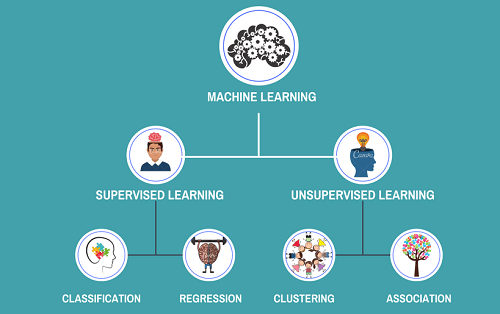
Supervised vs Unsupervised Learning: What's the Difference?
Imagine trying to learn a new language without a teacher. You’re handed a book with no translations or grammar tips—just pages of unfamiliar words. Sounds hard, right?
That’s kind of what unsupervised learning feels like to an algorithm. Now compare that to having a personal tutor who walks you through vocabulary, corrects your mistakes, and gives you quizzes. That’s more like supervised learning.
In the world of machine learning, supervised and unsupervised learning are two fundamental approaches. They’re the core pillars that guide how machines “learn” from data. If you’re new to the field or brushing up on the basics, knowing the difference between these two can give you a solid foundation to build more advanced knowledge.
Let’s break them down like two contestants in a learning showdown.
What is Supervised Learning?
Supervised learning is like learning with a guide or a teacher. The algorithm is trained on a labeled dataset, meaning each input has a corresponding output (or "answer") provided.
Real-World Analogy
Think of a student learning math by solving practice problems where each problem comes with the correct answer in the back of the book. The student knows when they’re right or wrong and can adjust accordingly.
How It Works
You feed the algorithm input-output pairs. Over time, it learns to predict the output from new inputs by minimizing the difference between its guesses and the actual answers.
Examples:
Email Spam Detection: The algorithm learns to classify emails as spam or not based on labeled examples.
Credit Scoring: It predicts if a customer is a credit risk using past labeled data.
Image Recognition: Like telling a system, “This is a cat,” or “This is a dog,” over and over.
Common Algorithms
Linear Regression
Logistic Regression
Decision Trees
Support Vector Machines (SVM)
Neural Networks
Pros of Supervised Learning
Clear feedback through labeled data.
High accuracy when trained properly.
Works well for classification and regression tasks.
Cons
Needs a lot of labeled data, which can be expensive or time-consuming to gather.
Can struggle with new, unseen data if it's not well-represented in the training set.
What is Unsupervised Learning?
Unsupervised learning is like being thrown into a new environment with no instructions—you learn by observing patterns and relationships on your own.
Real-World Analogy
Imagine walking into a room full of people speaking a language you don't understand. Over time, you might begin to identify patterns in the way words are used, group similar sounds together, or recognize emotional tone.
How It Works
The algorithm gets input data but no corresponding outputs. It explores the structure and patterns in the data without any guidance.
Examples
Customer Segmentation: Businesses use it to group customers based on purchasing behavior.
You want a model that can generalize well to new data.
When to Choose Unsupervised Learning
You’re exploring the data for insights.
You don’t have labeled data.
You want to find groupings or structures in your dataset.
Where They Cross Paths
Interestingly, the lines between the two aren’t always rigid. There are hybrid approaches:
Semi-Supervised Learning
Uses a small amount of labeled data with a large amount of unlabeled data. Think of it as supervised learning with a little help from unsupervised techniques.
Reinforcement Learning
It’s a different beast altogether where an agent learns through trial and error, using rewards and punishments.
Final Thoughts
Machine learning isn't a one-size-fits-all process. Choosing between supervised and unsupervised learning depends on your goals, your data, and what kind of insights you’re after. Think of supervised learning as a guided tour and unsupervised as an exploratory hike—you’ll learn something valuable either way.
If you're looking to understand these concepts in depth and apply them to real-world projects, enrolling in a Data Science course in Noida can be a great starting point.
So the next time someone throws around buzzwords like "clustering" or "regression," you’ll not only know what they mean—you’ll know when and why to use them.
FAQs
Q1: Is supervised learning always better than unsupervised learning? Not necessarily. Supervised learning is great for specific predictions, but unsupervised learning shines when you're exploring unknown patterns or structures in data.
Q2: Can I use both supervised and unsupervised learning in the same project? Absolutely! Many real-world systems combine both. For example, you might use unsupervised learning to group data and supervised learning to label and predict outcomes.
Q3: What if I don't have labeled data? Start with unsupervised learning or consider manually labeling a small portion of your data to build a supervised model.
Q4: How do I evaluate unsupervised learning results? Unlike supervised learning, you don’t have ground truth. You’ll use metrics like silhouette score, or rely on domain knowledge to interpret clusters.
Q5: What's the easiest algorithm to start with? For supervised, start with linear regression or decision trees. For unsupervised, try k-means clustering—it’s simple and widely used.
Stay curious, keep exploring, and don’t be afraid to try both paths. Machine learning is a journey, and every step teaches you something new.
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.