Tree Traversal in Data Structure: Inorder, Preorder, Postorder
The world of computer science is vast, but there are certain foundational concepts that every developer and data scientist must master. Among these, tree traversal in data structure stands as a cornerstone topic, playing a crucial role in areas ranging from algorithms to system design. Whether one is a student or a professional taking a Full Stack Developer Course in Noida, understanding how to navigate tree structures is an essential part of building a strong technical foundation.
Tree Traversal in Data Structure: Inorder, Preorder, Postorder
Mr. Bambam Yadav / 1 days
0
4 min read
This article takes a deep dive into the concept of tree traversal, breaking down the three main types: inorder, preorder, and postorder traversal. Readers will walk away with not only a clear understanding of the theory but also practical examples and insights on where and why these techniques matter in real-world development and system operations.
Introduction to Trees in Data Structures
A tree is a hierarchical data structure, widely used in computer science to represent relationships such as file systems, organizational charts, and decision processes. Unlike arrays or linked lists, where data is organized linearly, trees allow for branching connections between nodes. Each node can have child nodes, and the entire structure has one starting point called the root.
In a Full Stack Developer Course in Noida, students are introduced to various data structures, but trees are often given special attention because of their versatility. From representing hierarchical data to optimizing search and retrieval operations, trees form the backbone of many critical software systems. However, to work effectively with trees, one must understand how to systematically explore or visit their elements — this is where tree traversal comes into play.
What is Tree Traversal?
Tree traversal refers to the process of visiting all the nodes in a tree data structure, exactly once, in a particular order. This is important because unlike arrays or linked lists, where elements can be accessed directly via an index, tree nodes are connected hierarchically. One cannot simply “jump” to a node; instead, one must follow specific pathways through the tree.
The three main types of tree traversal in data structure — inorder, preorder, and postorder — each define a different visiting sequence. These traversal methods are fundamental not only for searching and sorting operations but also for tasks such as printing a tree’s contents, evaluating expressions, and serializing data structures for storage or transfer.
Inorder Traversal
Inorder traversal is perhaps the most well-known traversal technique, especially for binary search trees (BSTs). In an inorder traversal, the nodes are visited in the following sequence:
Visit the left subtree
Visit the current node (root)
Visit the right subtree
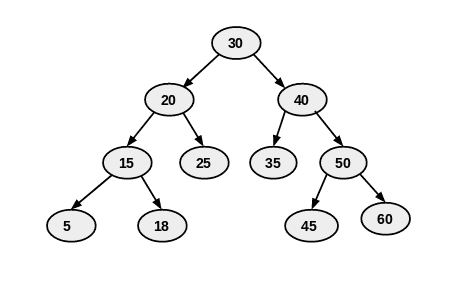
This order results in visiting the nodes in a sorted sequence if the tree is a BST. For example, consider a simple binary search tree with the values 2, 3, 5, 7, and 11. Using inorder traversal, the nodes would be visited in ascending order: 2, 3, 5, 7, 11.
In aFull Stack Developer Course in Noida, students often encounter inorder traversal when working on search and sort operations, database indexing, and expression trees. The key advantage of inorder traversal is that it retrieves data in a non-decreasing sequence, making it ideal for tasks requiring ordered data processing.
Example of Inorder Traversal
Consider the following binary tree:
5
/ \
3 7
/ \ \
2 4 11
Inorder traversal visits the nodes in this order: 2, 3, 4, 5, 7, 11.
Preorder Traversal
Preorder traversal takes a different approach by visiting the root node before its subtrees. Specifically, the sequence is:
Visit the current node (root)
Visit the left subtree
Visit the right subtree
Preorder traversal is particularly useful for tasks such as creating a copy of a tree, generating prefix expressions in compilers, and designing file system explorers.
In the Full Stack Developer Course in Noida, students are taught that preorder traversal is helpful when the root node’s processing must happen before any child nodes. This is common when building representations of hierarchical data, where the parent’s details must come before the child elements.
Example of Preorder Traversal
Using the same binary tree as above:
5
/ \
3 7
/ \ \
2 4 11
Preorder traversal visits the nodes in this order: 5, 3, 2, 4, 7, 11.
Postorder Traversal
Postorder traversal completes the visiting process by handling the root node last. The sequence is:
Visit the left subtree
Visit the right subtree
Visit the current node (root)
Postorder traversal is commonly used in applications such as deleting a tree (since children need to be deleted before their parents), evaluating postfix expressions, or performing certain types of dependency resolution tasks.
AFull Stack Developer Course in Noida often integrates postorder traversal into coursework on memory management, compiler design, and recursive algorithms, as it embodies a “bottom-up” approach to processing.
Example of Postorder Traversal
Again, using the same binary tree:
5
/ \
3 7
/ \ \
2 4 11
Postorder traversal visits the nodes in this order: 2, 4, 3, 11, 7, 5.
Comparing Inorder, Preorder, and Postorder Traversals
Although all three traversal methods ensure that each node is visited exactly once, the order of visiting nodes leads to different outcomes and use cases. The tree traversal in data structuretechnique chosen largely depends on the problem at hand.
Inorder traversal is ideal when sorted order is required. Preorder traversal is preferred when the parent node’s processing precedes its children, as in tree-copying tasks or hierarchical printing. Postorder traversal is useful when child nodes need to be processed before their parent, as in deletion or memory cleanup operations.
Students in a Full Stack Developer Course in Noida are often encouraged to not only understand these traversals theoretically but also practice implementing them in different programming languages such as Python, JavaScript, and Java. Mastering traversal techniques equips students with the ability to handle complex data structures efficiently.
Traversal Techniques in Practice
Implementing tree traversal requires understanding recursion, as trees are inherently recursive structures. For example, an inorder traversal function typically calls itself on the left subtree, processes the current node, and then calls itself on the right subtree. This pattern applies similarly to preorder and postorder traversals, with only the order of operations changing.
AFull Stack Developer Course in Noidaprovides students with numerous coding exercises to reinforce these concepts. Writing recursive functions not only strengthens students’ understanding of trees but also improves their problem-solving skills, which are critical in technical interviews and real-world development projects.
Applications in Full Stack Development
While tree traversal might seem like a theoretical topic, it has practical relevance across the software development landscape. In full stack development, trees are frequently encountered in JSON structures, HTML DOM trees, routing tables, and state management libraries.
For instance, when building a dynamic web application, developers often manipulate the Document Object Model (DOM), which is structured as a tree. Efficiently traversing and updating this tree is crucial for maintaining application performance. Similarly, in backend systems, tree traversals support tasks like database indexing, file system navigation, and optimizing query performance.
Students enrolled in a Full Stack Developer Course in Noidalearn that understanding traversal techniques helps them write more efficient code, especially when dealing with large-scale data operations or complex user interfaces.
Challenges in Tree Traversal
Despite its importance,tree traversal in data structurecomes with challenges. Recursive implementations can lead to stack overflow errors if the tree is too deep, which is why iterative approaches using stacks are sometimes preferred. Additionally, understanding the subtle differences between traversal methods can be confusing at first, especially for beginners.
Instructors in a Full Stack Developer Course in Noidaemphasize these challenges and guide students through debugging techniques, performance optimization, and memory management considerations when working with tree data structures.
Future Trends and Advanced Topics
As technology advances, trees and their traversal methods continue to play a role in cutting-edge applications such as machine learning, artificial intelligence, and blockchain systems. For example, decision trees in machine learning rely on traversal techniques to make predictions, while Merkle trees in blockchain use traversal for data verification.
Students who master basic traversal concepts can later explore advanced topics like balanced trees (AVL, Red-Black Trees), B-trees used in databases, and segment trees used in competitive programming. A solid understanding of tree traversal in data structureis thus a stepping stone to mastering more complex data structures and algorithms.
Conclusion
In conclusion, mastering tree traversal is essential for anyone serious about a career in software development, data science, or systems engineering. Whether using inorder, preorder, or postorder methods, understanding how to systematically visit and process tree nodes enables developers to build efficient, scalable solutions.
A Full Stack Developer Course in Noidaequips students with the knowledge and practical skills to implement these traversal techniques in real-world projects. By internalizing the patterns and applications of tree traversal, students not only enhance their coding abilities but also strengthen their problem-solving mindset, preparing them for challenges across the tech landscape.
As data structures continue to evolve and new applications emerge, the foundational principles of tree traversal will remain as relevant as ever. For students and professionals alike, investing time in mastering these concepts is a wise step toward a successful and fulfilling career in full stack development.
Placed Students
Our Clients
Partners
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.