What Is Big Data? Definition, Uses, & How It Works Explained

- Big Data
- Data Science
- predictive performance
Big Data refers to the massive and ever-growing amount of information generated every day from different sources like social media, sensors, business transactions, and more. This data comes in many forms—organized data like spreadsheets (structured), messy data like social media posts (unstructured), and everything in between (semi-structured). It’s so large and complex that traditional methods of storing and analyzing data can’t handle it effectively.
Thanks to advancements in technology, including smartphones, the Internet of Things (IoT), and artificial intelligence (AI), the availability of data is increasing rapidly. As the data grows, specialized tools and technologies are being developed to help businesses quickly process and analyze it. These tools allow companies to make better decisions and uncover valuable insights.
In simple terms, Big Data isn’t just about having a lot of data. It’s about using this data smartly—whether it’s for predicting trends, solving problems, or improving customer experiences. For example, Big Data plays a key role in machine learning and advanced analytics, helping businesses make informed decisions and stay ahead in a competitive world.
Examples of Big Data
Big Data can be one of a company’s most valuable resources. By analyzing it, businesses can uncover important insights about their customers, operations, and market trends. These insights help improve decision-making and drive success.
Here are some simple examples of how Big Data is transforming industries:
1. Understanding Customers Better
Companies track how people shop and what they buy to suggest personalized products, making customers feel like recommendations are made just for them.
2. Stopping Fraud in Its Tracks
By analyzing how customers typically pay, businesses can spot unusual patterns in real-time and prevent fraud before it happens.
3. Improving Deliveries
Delivery companies combine data about shipping routes, local traffic, and weather to make sure packages arrive faster and more efficiently.
4. Advancing Healthcare
AI tools analyze messy medical information like doctor notes, lab results, and research reports to discover better treatments and improve patient care.
5. Fixing Roads
Cities use camera and GPS data to find potholes and prioritize road repairs, making streets safer and smoother.
6. Protecting the Environment
Satellite images and geospatial data help organizations track the impact of their supply chains on the environment and plan more sustainable operations.
Characteristics of Big Data | The Vs of Big Data
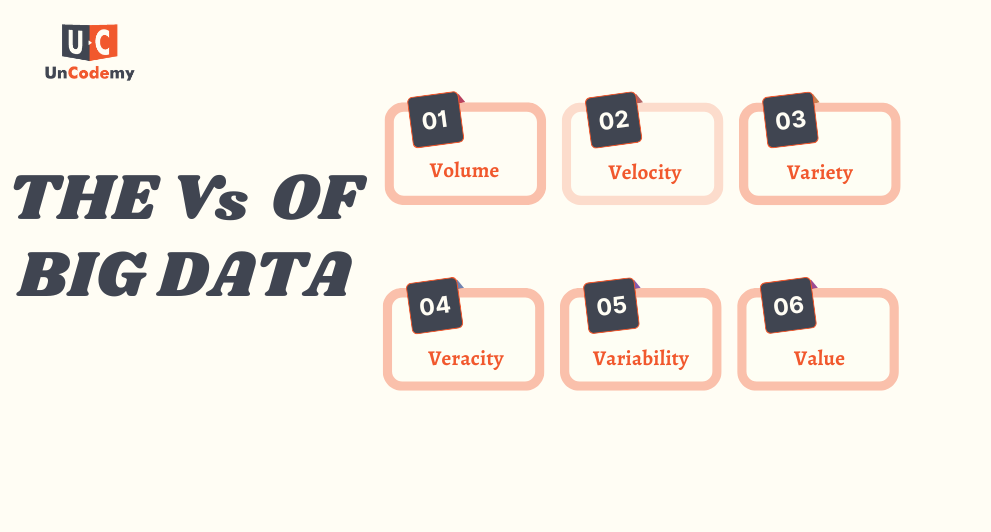
Big Data is often described using the 3 Vs—Volume, Velocity, and Variety—a concept first introduced by Gartner in 2001. Over time, additional Vs like Veracity, Variability, and Value have been added to capture the full scope of Big Data. Here’s what each of these means in simple terms:
1. Volume: The Massive Size of Big Data
- The sheer size of data is what makes it “big.” Every second, huge amounts of data are generated from devices, sensors, social media, and more. This massive amount of data is what businesses work to collect, store, and analyze.
2. Velocity: The Speed at Which Big Data Moves
- Data is being created at an incredible speed. Whether it’s real-time social media updates, sensor readings, or financial transactions, businesses need to process and analyze this data as fast as it comes in to make timely decisions.
3. Variety: The Diverse Forms of Big Data
Data comes in all shapes and forms. It can be:
- Structured: Data neatly organized in tables, like spreadsheets.
- Unstructured: Data like images, videos, or social media posts that don’t fit into a traditional format.
- Semi-structured: Data with some structure, like JSON files or sensor data.
This variety makes analyzing Big Data more complex but also more powerful.
4. Veracity: Ensuring the Accuracy of Big Data
- Not all data is reliable. Big Data can be messy, incomplete, or inaccurate, which can make analysis difficult. High veracity means the data is clean, accurate, and trustworthy enough to make good decisions.
5. Variability: How Big Data Context Can Change
- The meaning and context of data can change over time. For example, customer preferences may shift, or the type of data collected might evolve based on new trends. This variability makes it challenging to maintain consistency in analysis.
6. Value: Unlocking Insights from Big Data
- The most important aspect of Big Data is its ability to provide insights. Businesses need to focus on collecting the right data and analyzing it effectively to uncover patterns, solve problems, and make informed decisions.
How Does Big Data Work?
Big Data is all about using large amounts of information to gain a clearer understanding of situations, spot opportunities, and make better decisions. The idea is simple: the more data you have, the better insights you can uncover to improve your business.
Here’s how Big Data works, step by step:
1. Integration: Collecting Big Data from Multiple Sources
Big Data comes from many sources—websites, sensors, social media, and more. All this raw information needs to be collected, processed, and organized into a format that makes sense. This step ensures that analysts and decision-makers can start working with the data.
2. Management: Storing and Organizing Big Data Efficiently
Storing Big Data requires powerful systems because we’re talking about terabytes or even petabytes of data. Companies often use cloud storage, on-premises data centers, or a mix of both. The data must be stored in its raw or processed form and made available quickly, sometimes in real time. Cloud storage is becoming popular because it offers flexibility and can handle massive amounts of data without limits.
3. Analysis: Uncovering Insights from Big Data
The final and most important step is analyzing the data to find valuable insights. This could mean spotting trends, identifying opportunities, or solving problems. Tools like charts, graphs, and dashboards help businesses present these insights in a simple and clear way, so everyone in the organization can understand and act on them.
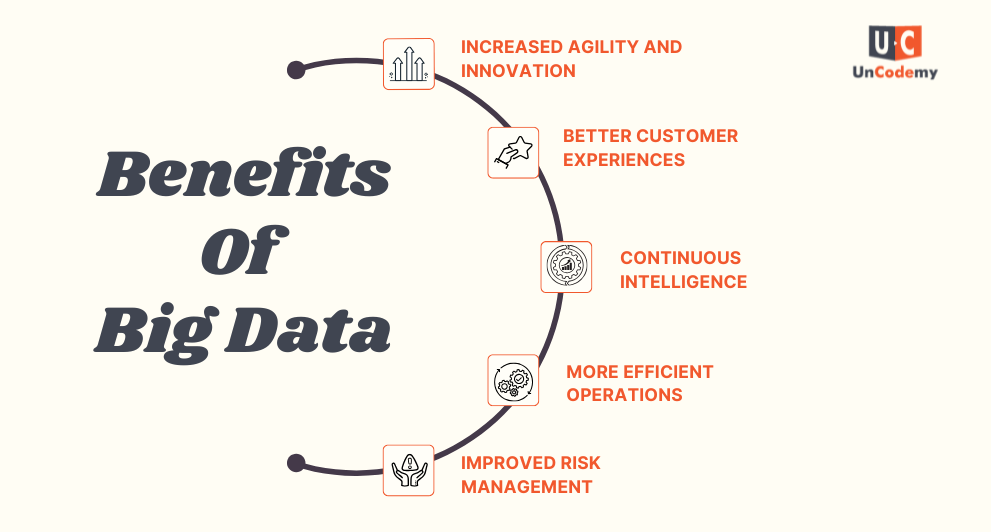
Big data helps businesses make smarter decisions. By analyzing large amounts of data, companies can find patterns and useful information that guide both day-to-day and long-term decisions.
1. Increased Agility and Innovation
With big data, businesses can analyze real-time data and adapt quickly to changes. This helps them launch new products or features faster and stay ahead of the competition.
2. Better Customer Experiences
By combining different types of data (like customer feedback and behavior), companies can understand their customers better, personalize offerings, and improve overall customer satisfaction.
3. Continuous Intelligence
Big data allows businesses to gather and analyze data in real-time, constantly discovering new insights and opportunities that help them grow and stay relevant in the market.
4. More Efficient Operations
Big data tools help companies analyze data quickly, which can reveal areas where they can cut costs, save time, and make their operations run smoother.
5. Improved Risk Management
By analyzing large amounts of data, businesses can better understand risks and take action to prevent potential problems. This leads to more effective strategies to manage and reduce risks.
Challenges of Big Data Analytics
While big data has many benefits, there are also some challenges that organizations face when working with such large amounts of data. Here are the common challenges:
1. Lack of Skilled Professionals
There aren’t enough data scientists, analysts, and engineers who have the skills to manage and analyze big data. These experts are in high demand, making it hard to find the right talent to fully benefit from big data.
2. Fast Data Growth
Big data grows quickly, and without the right infrastructure in place (for processing, storing, and securing the data), it can become overwhelming to handle. Managing the constant growth of data can be a huge challenge.
3. Data Quality Issues
Raw data can be messy and disorganized, making it difficult to clean and prepare for analysis. Poor data quality leads to inaccurate insights, which can affect decision-making and business strategies. If not cleaned up properly, the data becomes unreliable.
4. Compliance and Legal Challenges
Big data often includes sensitive information, which must be handled carefully to meet privacy and legal regulations. Companies need to ensure they follow rules regarding where and how data is stored and processed, such as data privacy laws and regulations.
5. Integration Difficulties
Data is often spread across multiple systems and departments, which makes it hard to bring everything together. To make the most of big data, organizations must find ways to integrate and connect all the data sources, which can be a complex task.
6. Security Risks
Big data contains valuable information, making it a target for cyber-attacks. Since the data is diverse and spread across many platforms, protecting it with solid security measures becomes a challenging task.
How Data-Driven Businesses Are Performing
While some businesses hesitate to fully embrace big data due to the time, effort, and resources required to implement it, the benefits of becoming a data-driven organization are clear. Many organizations struggle with changing established processes and adopting a data-first culture, but the payoff is significant.
Here’s how data-driven businesses are performing:
- 58% of companies that make decisions based on data are more likely to exceed their revenue targets compared to those that don’t.
- Businesses with advanced data insights are 2.8 times more likely to experience double-digit growth year-over-year.
- Data-driven companies typically see over 30% growth annually.
Big Data Strategies and Solutions
Building a solid big data strategy starts with understanding your goals, identifying specific use cases, and evaluating the data you currently have. You’ll also need to figure out if you need additional data and what new tools or systems you’ll require to achieve your business objectives.
Unlike traditional data management systems, big data tools are designed to handle large and complex datasets. These tools help manage the volume of data, the speed at which it’s made available for analysis, and the variety of data types involved.
For example, data lakes allow organizations to ingest, process, and store data in its native format, whether it’s structured, unstructured, or semi-structured. They serve as a foundation for running various types of analytics, including real-time analysis, visualizations, and machine learning.
However, it’s important to remember that there’s no one-size-fits-all approach for big data. What works for one company might not suit another’s needs.
Here are four key principles to consider when developing a big data strategy:
1. Open
Organizations need flexibility to build custom solutions using the tools they choose. As data sources grow and new technologies emerge, big data environments must be open and adaptable, allowing businesses to create the solutions they need.
2. Intelligent
Big data should leverage smart analytics and AI/ML to save time and improve decision-making. Automating processes or enabling self-service analytics can empower teams to work with data independently, reducing the reliance on other departments.
3. Flexible
Big data analytics should foster innovation, not limit it. Build a data foundation that offers on-demand access to compute and storage resources. Ensure that your data systems can be easily combined with other technologies to create the best solution for your needs.
4. Trusted
For big data to be valuable, it must be trusted. This means ensuring your data is accurate, secure, and relevant. Building trust into your data strategy is crucial, and security must be prioritized to ensure compliance, redundancy, and reliability.
Types of Big Data
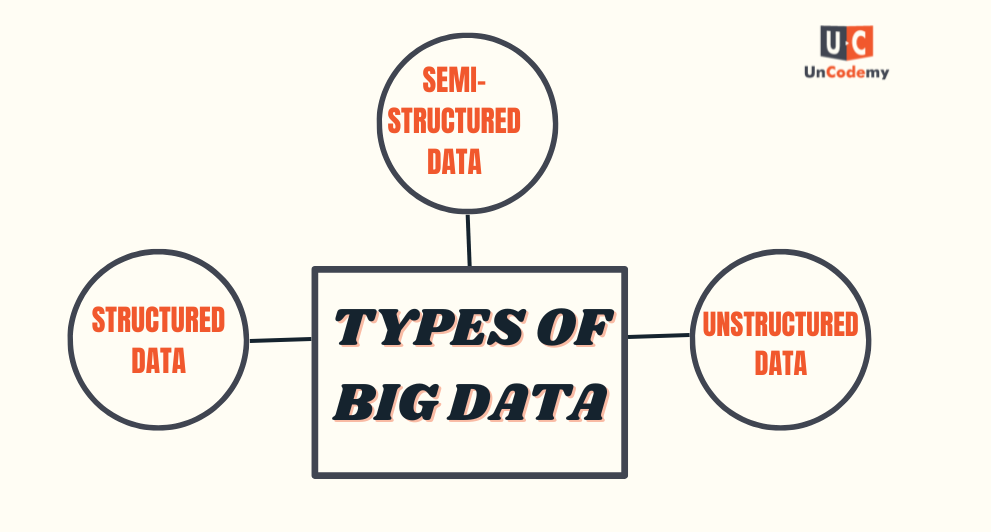
Big data can be categorized into three main types based on its structure and how it is stored and processed. These types are:
- Structured Data
- Unstructured Data
- Semi-Structured Data
1. Structured Data
Structured data refers to data that is highly organized and formatted in a way that makes it easy to store and analyze. It is typically stored in relational databases (RDBMS) or spreadsheets and can be easily processed by traditional data processing tools. Structured data is highly organized, with a predefined model that is easily understandable.
Characteristics of Structured Data:
- Well-organized: Data is arranged in rows and columns.
- Data type consistency: Each column has a specific data type (e.g., integers, strings, dates).
- Relational database format: Stored in tables with defined schemas.
Examples of Structured Data:
- Customer names, phone numbers, and addresses stored in a customer relationship management (CRM) system.
- Financial transactions in banks.
- Product information in an inventory system.
Technologies Used:
- Relational databases (e.g., MySQL, PostgreSQL, Oracle)
- SQL (Structured Query Language)
2. Unstructured Data
Unstructured data refers to data that has no predefined structure or organization. It is often difficult to process and analyze because it lacks a consistent format. Most of the data generated today is unstructured, and it often includes rich media like text, images, videos, and more.
Characteristics of Unstructured Data:
- Lacks organization: It does not follow a specific format.
- Complex data types: May include text, images, audio, video, logs, etc.
- Requires advanced processing techniques: Such data cannot be processed using traditional relational databases or tools.
Examples of Unstructured Data:
- Social media posts (tweets, Facebook status updates).
- Emails and messages.
- Audio and video files (e.g., podcasts, videos).
- Log files from servers and applications.
Technologies Used:
- NoSQL databases (e.g., MongoDB, Cassandra, HBase)
- Hadoop and Spark for large-scale processing
- Natural Language Processing (NLP) for text analysis
3. Semi-Structured Data
Semi-structured data is a hybrid form of data that does not have the strict structure of structured data, but it still contains some organizational elements that make it easier to analyze compared to unstructured data. This data type often includes tags, markers, or metadata that define elements and their relationships.
Characteristics of Semi-Structured Data:
- Some organization: It may have tags or markers (e.g., XML, JSON, etc.) that provide structure.
- Flexible format: It is not confined to the rigid schema of relational databases.
- Easier to parse and analyze: Semi-structured data can be processed using modern big data tools more efficiently than unstructured data.
Examples of Semi-Structured Data:
- XML files and JSON data (often used in APIs).
- Email with metadata (e.g., sender, recipient, subject).
- Web pages with embedded data (e.g., HTML code).
- Logs from applications in JSON format.
Technologies Used:
- NoSQL databases (e.g., MongoDB, CouchDB)
- XML, JSON parsers
- Hadoop and Spark for processing
Key Components and Techniques in Big Data

Under this heading, the major components and techniques involved in Big Data are:
Big Data Ecosystem and Architecture
The Big Data Ecosystem consists of a variety of interconnected technologies designed to handle the volume, velocity, and variety of data generated across multiple sources. Key components include data storage systems, data processing frameworks, data ingestion tools, and analytics platforms. Data in this ecosystem can range from structured data (like relational databases) to unstructured data (like social media posts, videos, and logs), requiring specialized technologies to manage and process it. The architecture is built around distributed systems, ensuring scalability, fault tolerance, and the ability to handle vast amounts of data efficiently. The architecture typically includes a mix of cloud computing platforms, data lakes, and distributed databases, enabling real-time data access and processing.
- Key Technologies:Hadoop, Apache Spark, NoSQL databases (like MongoDB and Cassandra), data lakes, and cloud platforms.
- Use Cases:From social media analytics to IoT data processing, the big data architecture enables a range of applications in education, healthcare, retail, and more.
- Importance:An effective big data architecture ensures that organizations can scale and innovate without being limited by infrastructure, allowing them to collect and process data from different sources to create meaningful insights.
Hadoop Ecosystem
The Hadoop Ecosystem is one of the most well-known and widely used frameworks for managing and processing big data. Hadoop is designed to handle large-scale data processing and storage through a distributed file system (HDFS). Its MapReduce processing engine breaks large tasks into smaller chunks, processing them in parallel across a cluster of computers. This approach provides high fault tolerance and scalability for big data workloads.
- Core Components:
- HDFS: Distributed storage system that breaks large files into smaller blocks and stores them across a cluster of machines.
- MapReduce: A computational model for processing large datasets in parallel.
- YARN: Resource management system that manages and allocates system resources across the Hadoop cluster.
- Advanced Tools:Tools like Hive, Pig, HBase, and Zookeeper allow users to interact with and process big data using SQL-like languages, data transformation scripts, and real-time data storage solutions.
- Learning Focus:Hadoop is a critical learning tool for anyone interested in big data as it lays the foundation for understanding distributed computing and data processing paradigms.
Apache Spark and Big Data Processing
Apache Spark is an open-source, high-performance big data processing engine known for its speed and ease of use. Unlike Hadoop’s MapReduce, which processes data in batches, Spark enables in-memory processing that significantly boosts performance. It supports a wide range of applications, including batch processing, real-time data streaming, and machine learning.
- Core Components:
- RDD: Resilient Distributed Datasets provide fault-tolerant and parallel processing of distributed data.
- DataFrames & Datasets: High-level abstractions for structured data with optimization and easy-to-use APIs.
- Spark SQL: Enables SQL-based querying for structured data, integrating seamlessly with relational databases.
- Use Cases:Real-time analytics, customer segmentation, stock market predictions, and machine learning workflows.
- Learning Focus:Spark is essential for learners focusing on real-time processing and scalable data applications, making it ideal for data scientists and engineers.
NoSQL Databases
NoSQL databases are designed to handle unstructured and semi-structured data that traditional relational databases cannot efficiently manage. These databases offer flexibility, horizontal scalability, and high performance, making them ideal for big data environments.
- Types of NoSQL Databases:
- Key-Value Stores: Store data as key-value pairs. Examples: Redis, Riak.
- Document Stores: Use formats like JSON or BSON. Example: MongoDB.
- Column-Family Stores: Store data in columns for analytics. Example: Cassandra.
- Graph Databases: Ideal for relationship-based queries. Example: Neo4j.
- Learning Focus:Essential for working with social media data, IoT logs, and other non-tabular formats, providing a foundation for scalable storage design.
Data Ingestion and Integration
Data ingestion involves collecting and transferring data from multiple sources into big data systems for processing. Effective ingestion systems are essential for handling both batch and real-time data from diverse sources.
- Tools for Data Ingestion:
- Apache Kafka: A distributed streaming platform for real-time data pipelines.
- Apache Flume: Used for aggregating log data, especially from servers.
- Apache Sqoop: Efficiently imports data from relational databases into Hadoop-based systems.
- Learning Focus:Helps learners understand how to collect, transform, and load data from diverse sources efficiently.
Batch vs Real-Time Data Processing
Big data can be processed in either batch or real-time, depending on the use case. Understanding both models is crucial to building effective data pipelines and analytics solutions.
- Batch Processing: Collects data over time for bulk processing. Tools: Hadoop, Spark.
- Real-Time Processing: Processes data as it arrives for immediate insights. Tools: Kafka, Storm, Flink.
- Learning Focus:Key to designing efficient systems based on the need for latency and volume of data.
Big Data Analytics
Big Data Analytics is used to extract valuable insights from massive datasets, aiding businesses in making data-driven decisions and uncovering trends, anomalies, and opportunities.
- Types of Analytics:
- Descriptive Analytics: Analyzes historical data to identify patterns.
- Predictive Analytics: Uses data to predict future outcomes.
- Prescriptive Analytics: Recommends actions based on data predictions.
- Tools: Hive, Pig, Spark MLlib, Tableau, Power BI.
- Learning Focus:Crucial for making strategic decisions in sectors like marketing, finance, healthcare, and education.
Machine Learning with Big Data
Machine learning in big data enables predictive analysis and automation using large datasets. It helps organizations build intelligent systems that improve decision-making.
- Tools for ML: Spark MLlib, TensorFlow, Scikit-learn.
- Use Cases: Recommendation engines, predictive maintenance, fraud detection, sentiment analysis.
- Learning Focus: Essential for aspiring data scientists and engineers aiming to build scalable ML models using distributed computing frameworks.
Data Visualization
Data Visualization transforms complex data into graphical formats, enabling stakeholders to easily interpret and act on insights.
- Tools: Tableau, Power BI, Qlik.
- Learning Focus: Helps in effectively communicating data findings to non-technical audiences and enhances decision-making.
Big Data in Cloud Computing
Cloud platforms provide scalable infrastructure for storing, processing, and analyzing big data. Cloud services support elasticity, cost-effectiveness, and on-demand resource availability.
- Key Services: AWS Redshift, Google BigQuery, Azure Synapse Analytics for warehousing; Data Lakes for raw storage.
- Learning Focus: Knowledge of cloud-based solutions is crucial as businesses increasingly move their data to cloud ecosystems.
Security and Governance in Big Data
Security and data governance ensure data privacy, compliance, and reliability in big data systems. They help manage access, enforce policies, and maintain data integrity.
- Tools: Apache Ranger, Kerberos, AWS IAM.
- Governance: Involves policy enforcement, classification, and regulatory compliance like GDPR or HIPAA.
- Learning Focus: Critical for protecting sensitive information and building trust in big data platforms.
Advanced Topics in Big Data
Advanced topics explore innovations in the big data domain, addressing modern challenges through cutting-edge technologies and methods.
- Emerging Trends: Edge computing, blockchain for data security, AI-powered analytics, quantum computing.
- Learning Focus: Keeping up with these trends is vital for professionals aiming to stay competitive in the evolving landscape of big data and AI.

























