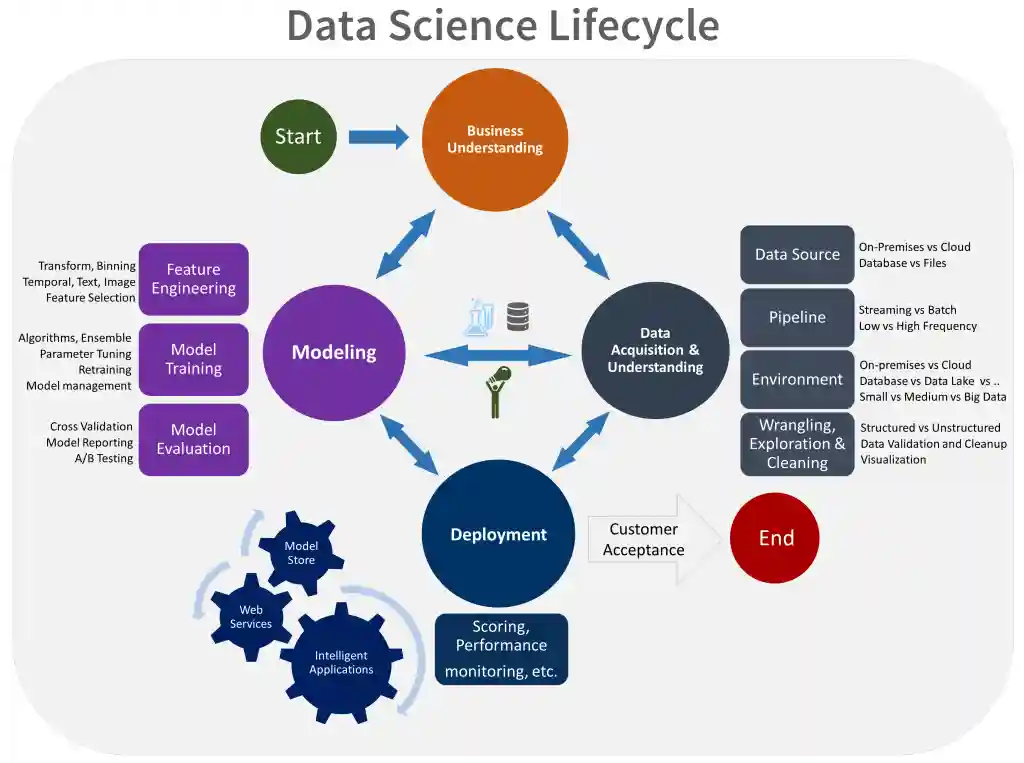
The Core Idea: Learning from Data and Optimization
At its fundamental level, model training is akin to teaching a student through repeated exposure to examples. You provide the chosen algorithm with a large volume of pre-processed data, known as the training dataset. The algorithm then iteratively adjusts its internal parameters – which can be anything from the weights and biases in a neural network to the coefficients in a linear model or the split points in a decision tree – to minimize a predefined "loss function" or "cost function." This loss function quantifies the discrepancy between the model's predictions and the actual, known outcomes in the training data. The entire training process is, therefore, an optimization problem: finding the set of parameters that make the model's predictions as close as possible to the ground truth.
Key Steps and Concepts in Model Training
The journey of model training is a multi-stage process, each step critical to building a robust and effective model.
1. Data Preparation (The Foundation)
Before any learning can occur, the data must be meticulously prepared. This aligns perfectly with the emphasis on "data cleaning and manipulation" found in "Practical & Tutorial-Oriented Blogs" for data science beginners.
· Data Cleaning: This involves identifying and handling imperfections in the data. This includes:
o Missing Value Imputation: Deciding how to fill in gaps in the dataset (e.g., with the mean, median, mode, or more sophisticated ML-based imputation techniques).
o Outlier Detection and Treatment: Identifying and addressing data points that significantly deviate from the norm, which can disproportionately affect model learning.
o Duplicate Removal: Ensuring unique records to prevent skewed results.
· Feature Engineering: This is often considered an art as much as a science. It involves creating new, more informative features from existing raw data. For example, combining date components to create "day of week" or "month" features, or deriving "average transaction value" from individual transactions. While traditionally manual, in 2026, AI tools and AutoML platforms are increasingly assisting in this crucial step, as highlighted in "Industry News & Trends Blogs."
· Data Transformation: Converting data into a format suitable for the chosen algorithm. Common transformations include:
o Scaling/Normalization: Adjusting numerical features to a common range (e.g., 0-1 or mean 0, standard deviation 1) to prevent features with larger values from dominating the learning process.
o Encoding Categorical Variables: Converting non-numerical categories (e.g., "red," "blue") into numerical representations (e.g., one-hot encoding).
· Data Splitting: To ensure the model generalizes well to unseen data, the dataset is typically divided into distinct subsets:
o Training Set (70-80%): The largest portion, exclusively used for the model to learn from.
o Validation Set (10-15%): Used during the training phase to tune hyperparameters and monitor the model's performance on data it hasn't directly learned from. This helps in preventing overfitting.
o Test Set (10-15%): A completely unseen portion of the data, reserved for the final, unbiased evaluation of the model's performance after training and tuning are complete. This set truly indicates how well the model will perform in the real world.
2. Algorithm Selection
The choice of ML or DL algorithm depends heavily on the problem type (e.g., predicting a continuous value like price - regression; classifying into categories like spam/not spam - classification; grouping similar data points - clustering) and the characteristics of the data. "Conceptual & Foundational Blogs" are excellent resources for understanding the strengths and weaknesses of various "ML algorithms" and "Deep Learning architectures."
3. Model Initialization
Before learning begins, the internal parameters of the chosen algorithm are initialized. For simpler models, this might be setting coefficients to zero. For neural networks, weights and biases are typically initialized randomly to break symmetry and allow for diverse learning paths.
4. Iterative Optimization (The Learning Loop)
This is the heart of the training process, especially for ML and DL models.
· Forward Pass: The model takes input data from the training set, processes it through its layers (in DL), and generates an output (a prediction).
· Loss Calculation: The model's prediction is compared to the actual known value from the training data, and a loss function calculates the error or discrepancy. Common loss functions include Mean Squared Error (for regression) or Cross-Entropy (for classification).
· Backward Pass (Backpropagation): This step is crucial for neural networks. The calculated loss is propagated backward through the network's layers. This process determines how much each internal parameter contributed to the error.
· Parameter Update (Optimization): An optimization algorithm (e.g., Gradient Descent, Adam, RMSprop) uses the information from the backward pass to adjust the model's parameters. The goal is to move the parameters in a direction that reduces the loss. This is an iterative process, where the model gradually learns to make better predictions.
· Epochs: An epoch represents one complete pass through the entire training dataset. The model typically undergoes many epochs, continuously refining its parameters with each pass.
5. Hyperparameter Tuning
Hyperparameters are configuration settings external to the model that are not learned from the data during training. Examples include the learning rate (how big of a step the optimizer takes during parameter updates), the number of hidden layers or neurons in a neural network, or the number of trees in a random forest. Tuning these hyperparameters is crucial for optimizing model performance. This is often done using the validation set and techniques like grid search, random search, or more advanced AI-powered AutoML methods, as noted in "Industry News & Trends Blogs."
6. Preventing Overfitting
A critical challenge in model training is overfitting, where the model learns the training data too well, including its noise and specific quirks, but performs poorly on new, unseen data. It essentially memorizes the training examples rather than generalizing patterns. Techniques to combat overfitting include:
· Regularization: Adding a penalty term to the loss function to discourage overly complex models (e.g., L1, L2 regularization).
· Cross-validation: A robust technique to evaluate model performance by training and testing on different subsets of the data multiple times, providing a more reliable estimate of generalization error.
· Early Stopping: Monitoring the model's performance on the validation set during training and halting the process when performance on the validation set starts to degrade, even if performance on the training set is still improving.
· Dropout (for Deep Learning): Randomly deactivating neurons during training to prevent co-adaptation and encourage robustness.
Why Model Training is Crucial in Data Science Projects
Model training is the heart of any predictive or analytical Data Science project because it enables:
· Robust Pattern Recognition: Allows algorithms to identify intricate, often non-obvious, patterns and relationships within massive and complex datasets that would be impossible for humans to discern.
· Accurate Predictive Power: A well-trained model can forecast future trends, classify new data points, or make informed decisions with a high degree of accuracy, providing tangible business value.
· Effective Generalization: The ultimate goal is to create a model that performs effectively on data it has never encountered before, making it truly useful in real-world applications.
· Automation of Intelligence: Once trained, the model can automate complex analytical tasks, providing insights or actions without constant human intervention, leading to increased efficiency and scalability.
Model Training in the Context of Uncodemy Courses
Uncodemy's comprehensive curriculum is meticulously designed to provide both theoretical understanding and hands-on practical experience in every aspect of model training:
· Uncodemy's Data Science Course: These flagship programs offer a holistic journey through the entire Data Science lifecycle, with a significant emphasis on model training. You'll gain a deep understanding of the theoretical underpinnings of various ML algorithms and acquire practical skills in implementing them using essential Python libraries like Scikit-learn, Pandas, and NumPy for data preparation, feature engineering, and model building. The curriculum is heavily project-based, ensuring you train and evaluate models on real-world datasets. This aligns with the "Practical & Tutorial-Oriented Blogs" that emphasize hands-on coding.
· Uncodemy's AI & Machine Learning Course: For those aiming to specialize in the cutting-edge aspects of AI, these courses delve into the intricacies of Machine Learning and Deep Learning. You will gain in-depth knowledge of neural networks, advanced ML algorithms, and work extensively with industry-standard frameworks like TensorFlow and PyTorch to train complex Deep Learning models for tasks such as image recognition, natural language processing, and generative AI. The focus here is on understanding the nuances of how these models learn, how to optimize their training process, and how to mitigate challenges like overfitting.
· Uncodemy's Python Programming Course: A strong foundation in Python is an absolute prerequisite for effective model training. This course ensures you have the core programming skills needed to manipulate data efficiently, write custom training loops when necessary, and effectively utilize the powerful ML and DL libraries that facilitate the entire model training process. As mentioned in the "Must-Read Blogs for Data Science Beginners in 2026," Python's "Extensive Ecosystem of Libraries" is crucial for this phase.
In conclusion, model training is the transformative phase in Data Science projects where data is imbued with intelligence. It's an iterative, optimization-driven process that requires a strong understanding of algorithms, meticulous data preparation, and techniques to ensure robust generalization. Mastering model training is a fundamental skill for any aspiring Data Scientist, and Uncodemy's specialized courses provide the comprehensive training necessary to excel in this critical domain.