When we talk about training machines to think or make decisions, we often expect them to perform as smartly as possible. But sometimes, they get too smart – and that’s not always a good thing. This is where the concept of overfitting enters the picture. If you're diving into machine learning (ML), overfitting is one of those fundamental things you really need to get a grip on – because it can literally break your model without you even realizing it.
Let’s break it all down – what overfitting really is, why it happens, how to spot it, and most importantly, how to fix or avoid it.
Overfitting happens when a machine learning model learns the training data too well – like too perfectly. It learns noise, random fluctuations, and minor details that don’t actually matter in the real world. As a result, when this model sees new, unseen data, it fails to generalize. It’s like someone memorizing the answers to one version of an exam – and then panicking when the questions are slightly different.
In simple terms:
Training Accuracy = Very high ✅
Test/Real-world Accuracy = Low ❌
The model is no longer learning patterns, it’s just memorizing.
Let’s Understand With an Example
Imagine you’re training a model to recognize whether a photo is of a cat or a dog.
If your model is underfitting, it might say “every animal is a dog” because it’s too simple.
If your model is just right, it’ll learn patterns like shape of ears, whiskers, or tail types.
If your model is overfitting, it’ll learn very tiny, irrelevant details like:
“Oh this cat has a shadow in the left corner – that must mean it’s a cat.” 😵💫
Now when it sees a new cat without that shadow, it gets confused.
Why Does Overfitting Happen?
There are a few main reasons why overfitting happens:
1. Too Complex Models
Deep neural networks with too many layers and neurons can learn every little pattern – even the useless ones.
2. Not Enough Training Data
If the dataset is too small, the model doesn’t have enough variety to learn general rules.
3. Too Many Training Epochs
If you train the model for too long, it starts to memorize instead of learning.
4. Noisy Data
If the training data has a lot of random or irrelevant information (like spelling mistakes, inconsistencies), the model might mistake these for patterns.
How to Know If Your Model Is Overfitting?
Here are some signs:
• Training accuracy is very high, but validation or test accuracy is much lower.
• Loss function is decreasing a lot on training data, but increasing on validation data.
• Model makes wrong predictions on real-world inputs, even if it performs great on your training set.
Imagine getting 100/100 on mock tests you memorized – and then failing your final because it had different questions. That’s overfitting.
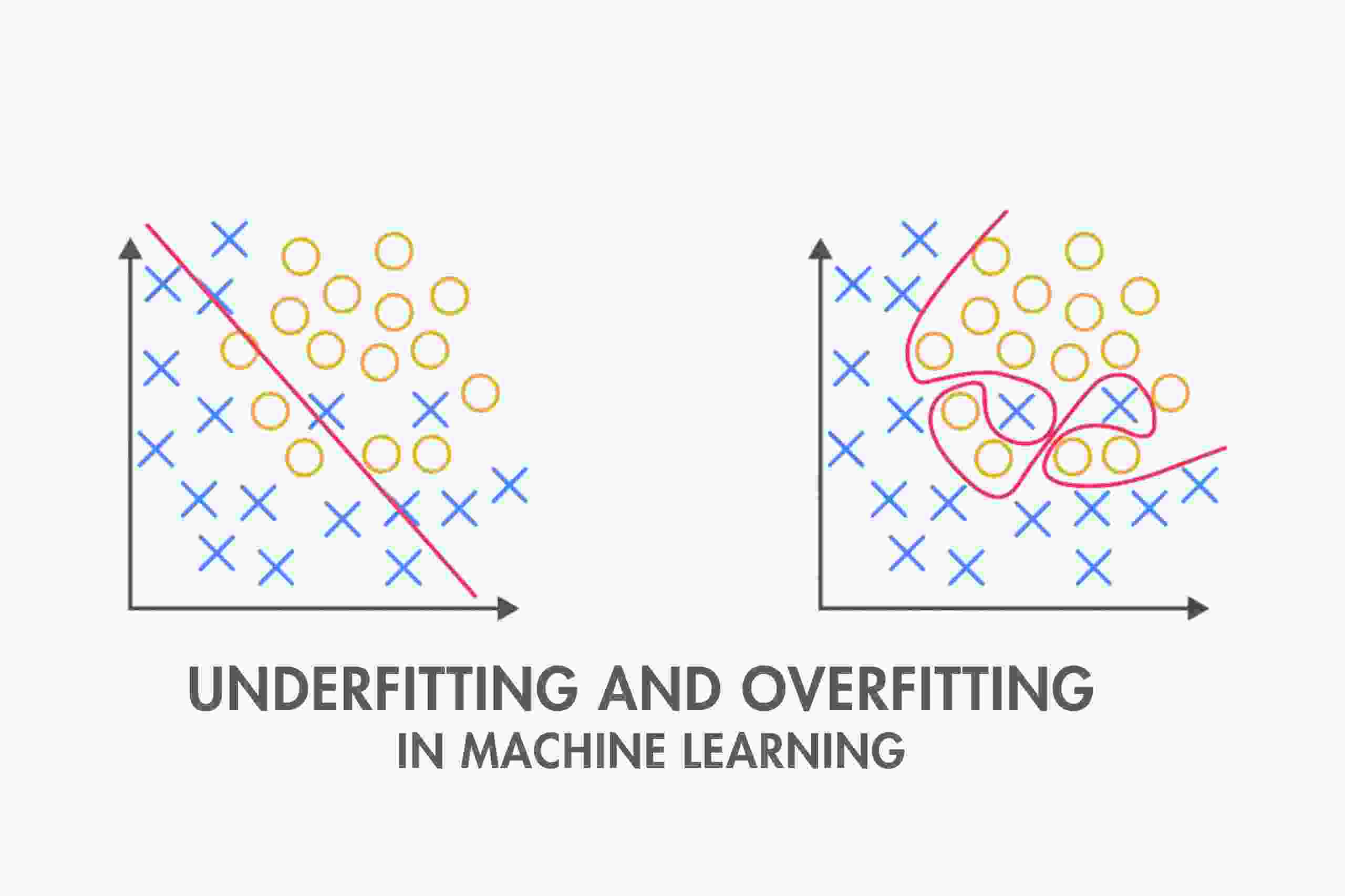
Visual Example (Imagine a Graph!)
Let’s say you have a scatter plot of points.
A simple model might draw a straight line that doesn’t really match the points but gets the idea.
A perfect model draws a curve that gently fits through the middle of the points.
An overfit model draws a crazy zigzag line touching every single point, even the outliers – because it’s trying too hard to be perfect. But it completely fails when given new data.
Techniques to Prevent or Fix Overfitting
Overfitting is super common, especially for beginners –but thankfully, there are many techniques to fight it.
1. Train with More Data
More diverse training data gives the model better chances to learn general patterns rather than memorizing.
2. Cross-Validation
Instead of just training and testing once, split your data into parts and train/test multiple times to ensure stability.
3. Regularization
This adds a penalty to the loss function to discourage overly complex models. Common types are:
L1 Regularization (Lasso)
L2 Regularization (Ridge)
Basically, it’s like telling the model: “Hey, don’t get too fancy.”
4. Early Stopping
Watch the validation accuracy during training. When it starts to go down (even if training accuracy still increases), stop training. You're about to overfit.
5. Dropout (for Neural Networks)
In deep learning, dropout randomly ignores a few neurons during training to avoid dependency on certain nodes. Think of it like forcing your brain to solve a problem with only half your notes.
6. Simplify the Model
If your model is too complex for the problem, try reducing the number of layers or features. Go minimal.
7. Data Augmentation (for images)
For tasks like image recognition, you can flip, rotate, or zoom your images to artificially create more diverse data.
Real-World Analogy
Think of a student preparing for an interview.
If they memorize exact answers word for word, they might freeze when the interviewer changes the question slightly (overfitting).
But if they understand the concepts and practice with a variety of questions, they’ll answer confidently no matter how it’s asked (generalization).
We want our machine learning models to be like that second student.
Overfitting vs Underfitting
Here’s a quick table to remember:
Feature
Overfitting
Underfitting
Training Accuracy
High
Low
Test Accuracy Low
Low
Low
Model Complexity
Too complex
Too simple
Real-world Performance
Poor
Poor
Solution
Simplify, regularize, more data
Increase complexity, train better
Real-World Impact and the Importance of Avoiding Overfitting
In the real world, overfitting isn't just a technical error–it can be the difference between a system that empowers decision-making and one that completely misleads it. Imagine a medical diagnostic model trained only on a specific hospital's patient data. If it overfits, it might perform well on those patients but fail dramatically when applied in a different region, potentially putting lives at risk. The same risk exists in financial predictions, fraud detection, and even personalized recommendations.
This is why researchers and developers are constantly trying to strike the right balance. They want models to be complex enough to capture meaningful patterns, but not so complex that they start "hallucinating" patterns in noise. It’s a bit like teaching a child – we want them to learn from experience, but not memorize every situation so rigidly that they panic when something new shows up.
Modern AI solutions now involve regularization techniques, dropout layers, and smarter validation methods to help minimize overfitting. Cross-validation is one of the most popular techniques because it tests the model on different subsets of the data, helping ensure generalization. Transfer learning, where a pre-trained model is fine-tuned on new data, is another great solution that reduces the chance of overfitting, especially when training data is limited.
At the end of the day, building a robust machine learning model is not about perfection on training data. It’s about learning well enough to face the unpredictable, messy, ever-changing real world. And that’s where the true intelligence lies.
Final Thoughts
Overfitting may sound like a technical glitch, but it actually reflects a deep and almost philosophical dilemma in machine learning – the tension between learning from the past and being open to the future. In a way, overfitting mirrors how we, as humans, sometimes rely too heavily on what we already know, making it harder to adapt when life throws something unexpected at us. Similarly, when an ML model clings too tightly to its training data, it fails to generalize – and that’s when things start to break down. This is one of the core concepts taught early in any well-structured Data Science and Machine Learning Course.
The more we learn about overfitting, the more it feels like a quiet reminder that intelligence, whether artificial or human, isn’t about being perfect. It’s about being flexible. A good model isn't one that memorizes every single training example – it’s one that understands enough to predict new outcomes without overreacting to noise. This balance between bias and variance is a foundational lesson emphasized throughout hands-on data science and machine learning training.
With technology evolving at breakneck speed, the importance of getting this right is only increasing. As machine learning gets embedded into healthcare systems, financial markets, education platforms, and even our day-to-day social media experiences, the cost of overfitting becomes more than just an accuracy percentage – it becomes a matter of fairness, safety, and trust. That’s why practical exposure in a Data Science and Machine Learning Coursefocuses not only on performance metrics, but also on responsible model development.
What fascinates me most is how many creative solutions exist to tackle this problem. From dropout to regularization, early stopping to cross-validation, the field keeps inventing smarter ways to help machines avoid this trap. These techniques are explored in depth during advanced modules of a comprehensive data science machine learning course, helping learners build models that are not just high-performing, but also reliable and scalable.
But maybe the most beautiful thing about this entire concept is how it reminds us of the limitations of AI – and the role of human judgment. Even the best algorithms can fall into traps, and that’s where our role comes in – to question, to test, to validate, and to improve. We are not just building systems that work – we are shaping systems that need to think better, a mindset reinforced through real-world projects in a Data Science and Machine Learning Course.
In the end, understanding overfitting isn't just about improving model performance. It’s about cultivating a mindset – one that embraces learning, but doesn’t get stuck in the past. One that values precision, but not at the cost of flexibility. Whether you’re an ML beginner, a data enthusiast, or someone exploring a data science machine learning course, this concept forms a foundation that’s critical for ethical and intelligent AI development.
So next time you see a perfectly trained model, pause for a second and ask: is it really learning – or is it just memorizing?
Because that one small difference can change everything 💪🏻💻
Placed Students
Our Clients
Partners
...
Uncodemy Learning Platform
Uncodemy Free Premium Features
Smart Learning System
Personalized learning paths with interactive materials and progress tracking for optimal learning experience.