In this blog, we’ll cover:
- What overfitting really means
- The reasons it occurs
- Real-world examples of overfitting in Machine Learning
- Effective strategies to avoid overfitting
- Best practices in the industry to build resilient models
And if you’re just starting out in Machine Learning or looking for some hands-on experience, signing up for a Machine Learning Course in Noida (uncodemy.com) can be a great way to get a solid grasp of these concepts with practical insights.
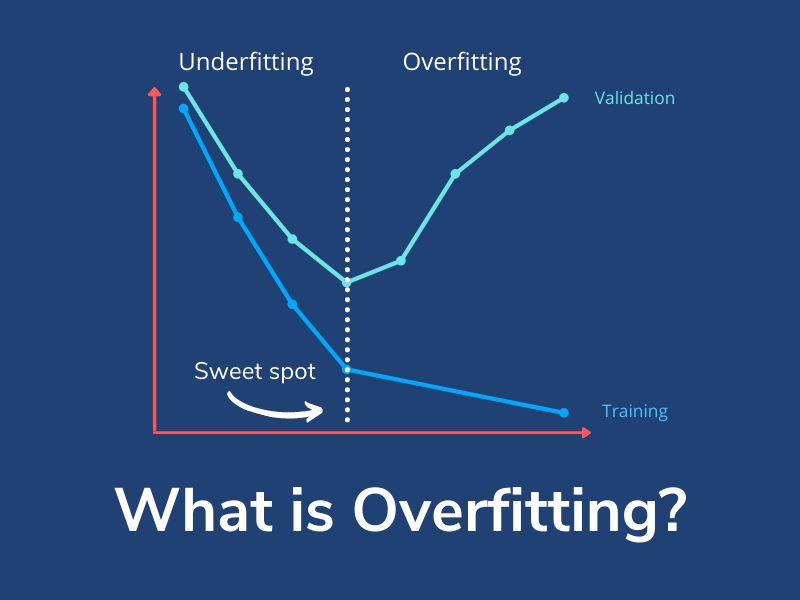
Understanding Overfitting in Machine Learning
At its essence, overfitting happens when a machine learning model becomes too familiar with the training data, picking up not only the key patterns but also the noise, outliers, and random variations.
This results in a model that performs exceptionally well on the training data but struggles to make accurate predictions on new or unseen data. To put it simply:
- Underfitting: The model is too basic → misses important patterns.
- Good Fit: The model captures key patterns and generalizes effectively.
- Overfitting: The model is overly complex → memorizes the training data and falters with new data.
Think of it like studying for a test by memorizing specific questions from a practice exam. If the actual test has the same questions, you’ll breeze through it. But if the questions are different, you’ll find yourself in a tough spot — that’s overfitting in action.
Why Does Overfitting Happen?
There are several reasons why overfitting can occur in Machine Learning:
Too Complex Model
- When you use deep decision trees, stack on too many layers in a neural network, or rely on high-degree polynomials, your model can become overly complicated.
- Instead of learning to generalize, the model ends up memorizing the training data.
Insufficient Training Data
- If you have a limited amount of data, the model might focus on noise rather than identifying real patterns.
- For instance, training an image recognition model with just 50 pictures can lead to this issue.
Too Many Features (High Dimensionality)
- Models that have a lot of features can easily pick up on irrelevant patterns.
- For example, including unnecessary details like "customer’s shoe size" when predicting loan approval can confuse the model.
Noise in Data
- Real-world datasets often come with errors, missing values, or inconsistencies.
- If the data isn’t cleaned up properly, the model might mistake noise for meaningful signals.
Excessive Training Epochs (in Deep Learning)
- Training for too long can cause the model to memorize the training examples.
- This is particularly common in neural networks if you don’t implement early stopping.
Examples of Overfitting in Machine Learning
Spam Detection
- A spam filter trained on a small set of spam emails might just memorize specific keywords.
- As a result, it may fail to classify real-world emails that use different phrases correctly.
Stock Market Prediction
- A model that’s trained on historical data might latch onto unusual price fluctuations (noise).
- Consequently, it struggles to predict future trends accurately.
Handwriting Recognition
- Overfitting can happen when the system memorizes the handwriting style from the training samples but has difficulty with new styles of handwriting.
How to Detect Overfitting?
Training vs. Validation Accuracy
- If your training accuracy is sky-high (like 98%) but your validation or test accuracy is lagging behind (say, around 65%), that’s a clear sign of overfitting.
Cross-Validation Results
- If your cross-validation scores are looking poor, it means the model isn’t really generalizing well.
Learning Curves
- A significant gap between the training and validation error curves is a telltale sign of overfitting.
High Variance in Predictions
- If your model gives inconsistent predictions across slightly different datasets, that’s another red flag.
How to Avoid Overfitting in ML?
The good news is that you can minimize overfitting with a variety of techniques. Let’s dive into some tried-and-true strategies:
1. Use More Training Data
- Feeding your model more data helps it learn generalized patterns instead of just memorizing.
- Data augmentation techniques, like rotating or flipping images, are commonly used in image recognition tasks.
2. Feature Selection
- Get rid of irrelevant or redundant features that don’t contribute anything valuable.
- Techniques like Principal Component Analysis (PCA) can help reduce dimensionality.
3. Regularization Techniques
- L1 (Lasso) and L2 (Ridge) Regularization penalize large coefficients in regression models.
- This helps keep the model from fitting to noise.
4. Cross-Validation
- Employ methods like k-fold cross-validation to evaluate model performance across various data subsets.
- This ensures your model generalizes well.
5. Early Stopping
- Stop training when the validation error plateaus, even if the training error keeps dropping.
- This helps prevent the model from memorizing the data.
6. Pruning in Decision Trees
- Decision trees can easily overfit by creating overly complex branches.
- Pruning helps trim unnecessary branches for better generalization.
7. Dropout in Neural Networks
- Randomly “drop” neurons during training to avoid co-dependency.
- This encourages neural networks to generalize rather than just memorize.
8. Ensemble Methods
- Techniques like Bagging, Random Forest, and Boosting combine multiple models to lower variance and combat overfitting.
9. Noise Injection
- Introduce random noise into the training data to enhance the model's robustness.
- This technique is often used in models for image and audio recognition.
10. Hyperparameter Tuning
- If hyperparameters are overly fine-tuned, it can lead to overfitting.
- Employ grid search or random search methods to discover well-balanced values.
Best Practices from Industry
- Companies like Google and Amazon utilize ensemble methods to prevent their recommendation systems from overfitting.
- In healthcare, machine learning models heavily depend on cross-validation due to the limited availability of patient data, where high variance can be risky.
- Self-driving cars make extensive use of dropout and data augmentation to adapt to a variety of real-world conditions.
By adopting these practices, organizations can implement dependable machine learning solutions that perform effectively beyond their training environments.
Why Understanding Overfitting Matters?
Overfitting has a direct effect on business decisions:
- A bank might mistakenly approve loans that are too risky.
- A medical diagnosis system could incorrectly diagnose patients.
- A recommendation engine might suggest irrelevant items, leading to decreased customer satisfaction.
Therefore, mastering the detection and prevention of overfitting is not just a technical necessity; it’s crucial for business success.
If you’re eager to gain practical experience with real projects, consider enrolling in a Machine Learning Course in Noida (uncodemy.com) to tackle challenges like overfitting, underfitting, and hyperparameter optimization.
Conclusion
Overfitting is one of the most prevalent challenges in machine learning, but with the right strategies—like cross-validation, regularization, dropout, and pruning—it can be effectively managed. The goal is to create models that generalize well to new data while striking a balance between complexity and performance.
By mastering techniques to prevent overfitting, you can develop machine learning models that are not only accurate during training but also truly reliable in real-world applications.
FAQs on Overfitting and How to Avoid It in ML
Q1. What is overfitting in ML in simple words?
Overfitting happens when a model nails the training data but struggles with new or unseen data because it’s just memorized the details instead of picking up on the actual patterns.
Q2. How is overfitting different from underfitting?
- Overfitting: The model is too complex and ends up memorizing the noise.
- Underfitting: The model is too simple and misses the patterns entirely.
Q3. Can deep learning models be more prone to overfitting?
Absolutely! Deep learning models, especially those with lots of layers and parameters, can easily overfit unless you use techniques like dropout or early stopping.
Q4. What role does regularization play in avoiding overfitting?
Regularization helps by penalizing overly complex models, pushing them towards simpler designs that generalize better.
Q5. How do I know if my model is overfitting?
If you see that your training accuracy is high but your validation/test accuracy is much lower, that’s a clear sign your model is overfitting.