If you're enrolled in a Big Data Course, a Data science course in Noida, or even just curious about how data really works behind the scenes, understanding this concept can be a real game-changer for your learning journey.
So, What Exactly Is Veracity in Big Data?
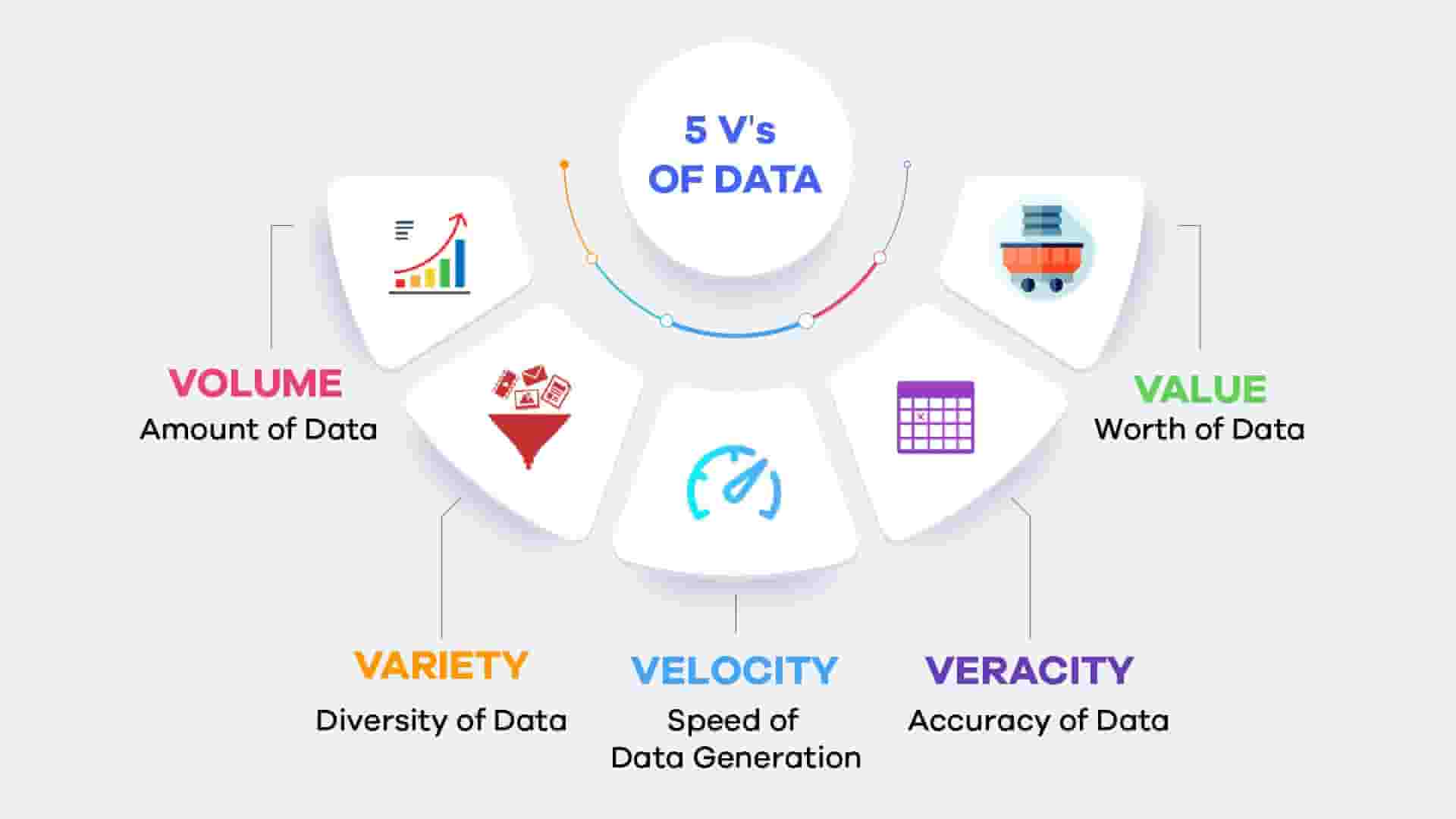
To put it simply, veracity refers to how trustworthy or reliable data is. When we talk about big data, we usually hear terms like volume, velocity, and variety—all about how much data there is, how fast it’s coming in, and in how many different forms.
But veracity? It’s all about the quality.
Imagine you're trying to plan a trip based on Google Maps, but half the road names are wrong and the estimated times are outdated. Not very helpful, right? That’s what bad data feels like.
Why Should You Care About Veracity?
The consequences of using flawed data can be pretty serious. A retailer might stock the wrong items based on faulty sales data. A hospital could administer incorrect medication if a patient's data isn't accurate. Or a company might make a poor business move simply because the numbers were off.
High-veracity data means fewer mistakes, more confident decisions, and greater trust in the system.
If you're pursuing a Big Data Course, you’ll definitely encounter this. Professors and industry experts stress it again and again: you can have all the data in the world, but if you can’t trust it, it’s basically useless.
The Hidden Challenges of Veracity
Maintaining accurate data isn't easy. Here are a few reasons why:
1. Data Comes From Everywhere
Businesses pull information from websites, sensors, social media, surveys, and even handwritten notes. No wonder things get messy.
2. Humans Make Mistakes
Manual data entry is still common. Even a simple typo can lead to costly errors if it’s not caught in time.
3. Bias Creeps In
Whether we like it or not, data collection can be influenced by bias—what questions we ask, who we ask them to, or what we choose to ignore.
4. Data Changes Constantly
What’s true today might not be true tomorrow. Outdated information is a real problem in fast-moving industries.
5. Missing or Incomplete Info
Sometimes, you just don’t get the full picture. Maybe a survey respondent skips a few questions. Maybe a sensor loses signal. Those gaps add up.
Everyday Examples of Veracity Issues
Let’s bring this down to earth. Here are a few real-world situations where data veracity plays a huge role:
- E-commerce: Let’s say an online shop notices a sudden dip in sales. But later they find out the analytics tool was misconfigured. The data was wrong, and so was the panic.
- Healthcare: Doctors depend on patient records to make life-saving decisions. If those records have even small errors, the results could be dangerous.
- Social Media Sentiment: Brands use tools to analyze public opinion. But what if a sarcastic tweet is flagged as negative when it was actually positive? That’s low veracity in action.
How Can Companies Improve Veracity?
Fixing veracity issues doesn’t mean you need the fanciest AI tools in the world. It often comes down to the basics:
- Cleaning Your Data Regularly: Think of it like washing dishes—tedious, but necessary.
- Using Clear Data Standards: If everyone uses the same formats, labels, and methods, there’s less room for confusion.
- Investing in Training: Sometimes, the best way to improve data quality is simply to teach employees how to handle it better.
- Automation: Validating entries automatically and flagging inconsistencies can save tons of time.
- Transparency: Always keep track of where your data comes from and how it’s been processed.
How Veracity Is Taught in a Big Data Course
Most Big Data Courses now include entire modules on data quality and veracity. Why? Because no matter how powerful your algorithms are, if your data is faulty, your results will be too.
These courses usually cover:
- Data cleaning tools and techniques
- How to handle missing or duplicate data
- Methods for evaluating data sources
- Real-life case studies where veracity either saved or ruined projects
If you're planning to work in fields like data science, analytics, or AI, this knowledge is more than helpful—it's essential.
Final Thoughts
So, the next time someone talks about how “data never lies,” maybe take it with a grain of salt. Data can absolutely be misleading if it’s not verified or cleaned properly.
That’s why veracity in big data is such a vital concept. And if you're serious about a career in data or just starting out with a Big Data Course, remember this: it’s not about having more data—it’s about having the right data.
After all, a single truth is worth more than a thousand wrong numbers.
Frequently Asked Questions (FAQs)
Q1: What does ‘veracity’ mean in the context of big data?
A: In big data, veracity refers to the trustworthiness, quality, and accuracy of data. It determines whether the data can be relied upon to make meaningful decisions.
Q2: How is veracity different from other big data ‘V’s like volume or velocity?
A: While volume refers to the amount of data, velocity to the speed of data generation, and variety to the types of data, veracity is focused entirely on the quality and reliability of that data.
Q3: Why is veracity important for organizations?
A: Without veracity, even the most advanced analytics models can produce misleading or harmful results. High-veracity data ensures better decisions, reduced risk, and improved outcomes across business, healthcare, finance, and more.
Q4: What causes low veracity in data?
A: Common causes include:
- Human errors in data entry
- Incomplete or outdated data
- Sensor malfunctions
- Biased data collection methods
- Poor data integration from multiple sources
Q5: Can automation help improve data veracity?
A: Yes. Automation can:
- Flag inconsistent or missing values
- Validate data against predefined rules
- Standardize formats
- Reduce manual input errors
These steps make it easier to maintain cleaner, more reliable datasets.
Q6: What tools are used for ensuring data veracity?
A: Popular tools include:
- Data wrangling tools (e.g., Trifacta, Talend)
- ETL platforms (e.g., Apache NiFi, Informatica)
- Data validation libraries (e.g., Pandera, Great Expectations)
- Profiling and cleaning tools (e.g., OpenRefine, Alteryx)
Q7: How do Big Data Courses teach about veracity?
A: Courses typically cover:
- Real-world case studies involving data quality issues
- Data cleaning and transformation techniques
- Handling missing or biased data
- Best practices for ensuring trust in data sources
Q8: What are real-life consequences of ignoring veracity?
A: Ignoring data veracity can lead to:
- Wrong business decisions
- Financial loss
- Medical misdiagnoses
- Customer dissatisfaction
- Regulatory non-compliance
Q9: How can a business measure data veracity?
A: Businesses often use data quality metrics, such as:
- Completeness
- Consistency
- Accuracy
- Timeliness
- Uniqueness
Regular audits and quality dashboards help track these metrics.
Q10: Is high-veracity data always available?
A: Not always. Achieving high veracity requires intentional effort, including proper data collection, cleansing, validation, and governance. It’s a continuous process, not a one-time fix.